Bayesian Structural Causal Inference#
import warnings
import arviz as az
import numpy as np
import pandas as pd
import pymc as pm
import pymc_bart as pmb
import pytensor.tensor as pt
import statsmodels.formula.api as smf
from matplotlib import pyplot as plt
warnings.filterwarnings("ignore", category=UserWarning)
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
When we ask “What is the effect of a medical treatment?” or “Does quitting smoking cause weight gain?” or “Do job training programs increase earnings?”, we are not simply asking about the treatment itself. We are asking: What world are we operating in? This perspective is more easily seen if you imagine a causal analyst as a pet-shop owner introducing a new fish to one of their many acquariums. The new fish’s survival and behavior depend less on its intrinsic properties than on how it fits within this complex, interconnected system of pH balances and predators. In which tank will the new fish thrive?
Different causal methods make different choices about how much of this system to model explicitly. Some methods succeed by not modeling the full system: instrumental variables isolate causal effects through credible exclusion restrictions; difference-in-differences leverages parallel trends; interrupted time-series assumes stationarity. These design-based approaches gain power by minimizing modeling assumptions about the data-generating process. See Pearl [2000] or Angrist and Pischke [2009] for more detailed distinctions. The unifying thread between these diverse methods is the idea of a causal model as a probabilistic program : an inferential routine designed to explicitly yield insights into the effect of some intervention or treatment on the system of interest. Whether design based or model-based, causal inference methods assume a data generating process - the distinction between these methods is how explicitly the system is rendered.
Modelling Worlds and Counterfactual Worlds#
Bayesian structural modeling attempts to parameterize the system itself. Where design-based methods answer “what is the causal effect under these identification assumptions?”, structural models ask “what is the most plausible data-generating process, and how do interventions propagate through it?”. In Bayesian structural causal inference the focus is slightly different in that we wish to model both the treatment and the environment i.e. the fish and the fishtank. The trade-off is transparency for complexity. You must specify more of the data-generating process, which creates more opportunities for model misspecification. But every assumption becomes an explicit, testable model component rather than an implicit background condition.
This is a two step move in the Bayesian paradigm. First we infer “backwards” what is the most plausible state of the world \(w\) conditioned on the observable data X, T, O. The “world” of the model is defined by: (1) a causal graph relating variables, (2) likelihood functions specifying how each variable depends on its causes, and (3) prior distributions over parameters. Optionally, this may include latent confounders, measurement models, and selection mechanisms—each adding structural detail but also complexity. With this world \(w = \{ \alpha, \beta_{1}, \beta_{2} ... \}\) in place, we continue to assess the probabilistic predictive distribution of treatment and outcome at the plausible range of counterfactual worlds.
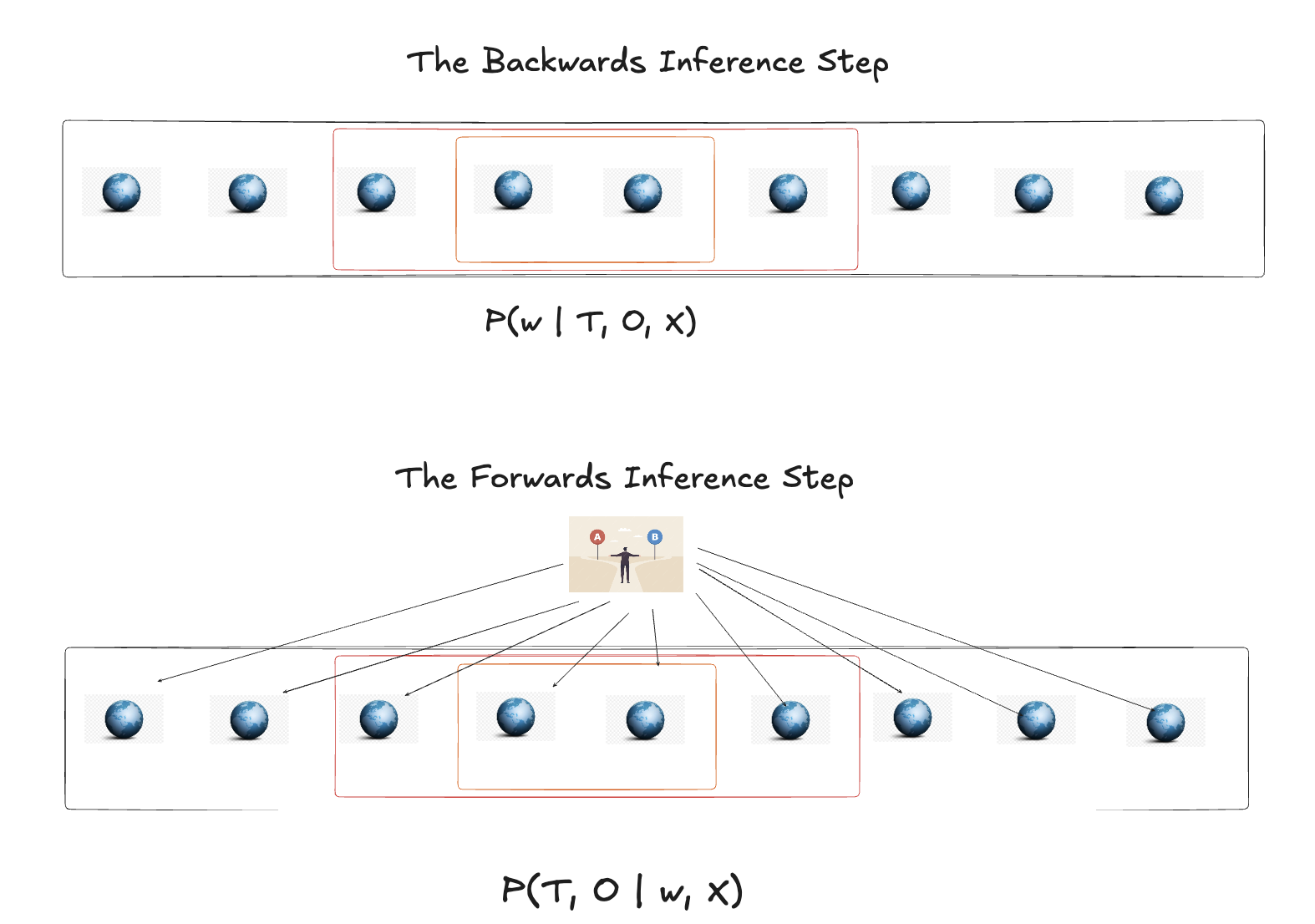
The important point is that we characterise the plausible worlds by how much structure we learn about in the model specification. The more structure we seek to infer, the more we risk model misspecification, but simultaneously, the more structure we learn the more useful and transparent our conclusions. This structural commitment contrasts sharply with reduced-form approaches that minimize explicit modeling.
Minimalism and Structural Maximalism#
The term “reduced form” originates from econometric simultaneous equations models. Early economists wanted to model supply and demand as functions of price, but faced a problem: quantities also determine price in competitive markets. Because these structural relationships are mutually determined, the system is hard to solve directly. The solution was algebraic transformation: solve for the ‘reduced form’ that expresses endogenous variables purely as functions of exogenous ones.
Reduced form systems are transformed systems of interest designed to estimate the focal parameters by leveraging observable and tractable data. These approaches eschew “theory driven” model specifications in favour of models with precise identifiable estimands. This approach - transforming complex structural systems into tractable estimating equations - reflects a broader methodological commitment. It is for this minimalist preference that they are typically contrasted with structural models that aim to express the “fuller” data generating process. Design based causal inference methods typically adopt this focus on identifiability within a regression framework. For richer discussion in this vein see Hansen [2022] or Aronow and Miller [2019].
When we regress an outcome \(Y\) on a treatment \(T\) and a set of covariates \(X\),
the coefficient \(\alpha\) captures the average change in Y associated with a one-unit change in \(T\). Only under strong assumptions, however, can we interpret this as a causal effect. In real-world settings, those assumptions (like exogeneity of \(T\)) are fragile:
Confounding: Unobserved or omitted variables affect both \(T\) and \(Y\).
Endogeneity: Treatment assignment mechanisms are correlated with the error term.
Measurement uncertainty: Model parameters and predictions have uncertainty not captured by point estimates.
The innovative methods of inference (like Two-stage least squares, propensity score weighting or DiD designs) that came to define the credibility revolution in the social sciences, seek to overcome this risk of confounding with constraints or assumptions to bolster identification of the causal parameters. See See Angrist and Pischke [2009]. Bayesian probabilistic causal inference addresses these challenges by explicitly modelling the data-generating process and quantifying all sources of uncertainty. Rather than point estimates and design assumptions, we infer full posterior distributions over causal parameters and even over counterfactual outcomes. Rather than isolating the outcome equation from the treatment equation, we model them together as parts of a single generative system. This approach mirrors how interventions occur in the real world. The propensity for adopting a treatment can be predicted by the same factors which determine treatment outcomes. This structure creates the risk of confounding because the efficacy of the treatment is obscured by the influence of these shared predictors. When we fit such a model, we learn about every component simultaneously—the effect of the treatment, the influence of confounders, and the uncertainty that ties them together. Once fitted, Bayesian models can generate posterior predictive draws for “what if” scenarios. This capacity lets us compute causal estimands like the ATE or individual treatment effects directly from the posterior.
In this tutorial, we’ll move step by step from data simulation to Structural Bayesian Causal models:
The Structure of the Document
Simulate data with known causal structure (including confounding and exclusion restrictions).
Fit and interpret Bayesian models for continuous treatments.
Extend to binary treatments and potential outcomes.
Use posterior predictive imputation to simulate counterfactuals.
Demonstrate the relationship between the structural modelling perspective with the potential outcomes framework.
Apply the model to an empircal example with parameter recovery checks and sensitivity analysis
This approach will show how Bayesian methods provide a unified and transparent lens on causal inference. We will cover estimation, identification, and uncertainty in a single coherent framework. The goal is to demonstrate how model comparison and sensitivity analysis, core components of the contemporary Bayesian workflow, are uniquely suited to causal inference. By treating our models as probabilistic programs we can interrogate each under different assumptions, priors and specifications. The Bayesian framework of joint structural modelling makes transparent what most causal analyses leave implicit: which conclusions follow from data, and which follow from structural commitments.
Simulating the Source of Truth#
Every causal claim rests on untestable assumptions about the data-generating process. Before we can trust our methods in the wild, we must test them in controlled conditions where truth is known. The simulation below constructs such a laboratory: we specify the causal structure explicitly, introduce confounding deliberately, and then ask whether our Bayesian models recover what we seeded in the data.
np.random.seed(123)
def inv_logit(z):
"""Compute the inverse logit (sigmoid) of z."""
return 1 / (1 + np.exp(-z))
def standardize_df(df, cols):
means = df[cols].mean()
sds = df[cols].std(ddof=1)
df_s = (df[cols] - means) / sds
return df_s, means, sds
def simulate_data(n=2500, alpha_true=3.0, rho=0.6, cate_estimation=False):
# Exclusion restrictions:
# X[0], X[1] affect both Y and T (confounders)
# X[2], X[3] affect ONLY T (instruments for T)
# X[4] affects ONLY Y (predictor of Y only)
betaY = np.array([0.5, -0.3, 0.0, 0.0, 0.4, 0, 0, 0, 0]) # X[2], X[3] excluded
betaD = np.array([0.7, 0.1, -0.4, 0.3, 0.0, 0, 0, 0, 0]) # X[4] excluded
p = len(betaY)
# noise variances and correlation
sigma_U = 3.0
sigma_V = 3.0
# design matrix (n × p) with mean-zero columns
X = np.random.normal(size=(n, p))
X = (X - X.mean(axis=0)) / X.std(axis=0)
mean = [0, 0]
cov = [[sigma_U**2, rho * sigma_U * sigma_V], [rho * sigma_U * sigma_V, sigma_V**2]]
errors = np.random.multivariate_normal(mean, cov, size=n)
U = errors[:, 0] # error in outcome equation
V = errors[:, 1] #
# continuous treatment
T_cont = X @ betaD + V
# latent variable for binary treatment
T_latent = X @ betaD + V
T_bin = np.random.binomial(n=1, p=inv_logit(T_latent), size=n)
alpha_individual = 3.0 + 2.5 * X[:, 0]
# outcomes
Y_cont = alpha_true * T_cont + X @ betaY + U
if cate_estimation:
Y_bin = alpha_individual * T_bin + X @ betaY + U
else:
Y_bin = alpha_true * T_bin + X @ betaY + U
# combine into DataFrame
data = pd.DataFrame(
{
"Y_cont": Y_cont,
"Y_bin": Y_bin,
"T_cont": T_cont,
"T_bin": T_bin,
}
)
data["alpha"] = alpha_true + alpha_individual
for j in range(p):
data[f"feature_{j}"] = X[:, j]
data["Y_cont_scaled"] = (data["Y_cont"] - data["Y_cont"].mean()) / data[
"Y_cont"
].std(ddof=1)
data["Y_bin_scaled"] = (data["Y_bin"] - data["Y_bin"].mean()) / data["Y_bin"].std(
ddof=1
)
data["T_cont_scaled"] = (data["T_cont"] - data["T_cont"].mean()) / data[
"T_cont"
].std(ddof=1)
data["T_bin_scaled"] = (data["T_bin"] - data["T_bin"].mean()) / data["T_bin"].std(
ddof=1
)
return data
Each simulated observation has a treatment \(T\), an outcome \(Y\), and a set of covariates \(X\) with distinct causal roles. Two covariates influence both the treatment and the outcome—these are the confounders. Two others affect only the treatment and serve as valid instruments. A final covariate affects only the outcome. The treatment and outcome errors are drawn from a correlated bivariate normal distribution, introducing endogeneity through their correlation parameter \(\rho\). When \(\rho\) is low the treatment can be considered exogenous and standard regression should recover the correct effect; while naive estimates will be biased when \(\rho\) is high.
Confounding Structure#
The function produces both continuous and binary versions of the treatment and the outcome. This dual design lets us explore two worlds side by side: one where the treatment is a continuous dosage, and another where it is a binary decision. In both cases, the true causal effect of the treatment on the outcome is set to three. Because we know the truth, we can evaluate how well our Bayesian models recover true parameters. Even here you can see that the “structure” we impose on the world is abstraction over the concrete mechanisms acting in the world. We bundle the idea of selecting into the treatment as potential for correlation between treatment and outcome. This is a convenient and tractable proxy of a range of concrete settings where there is a risk of selection effects in the real world.
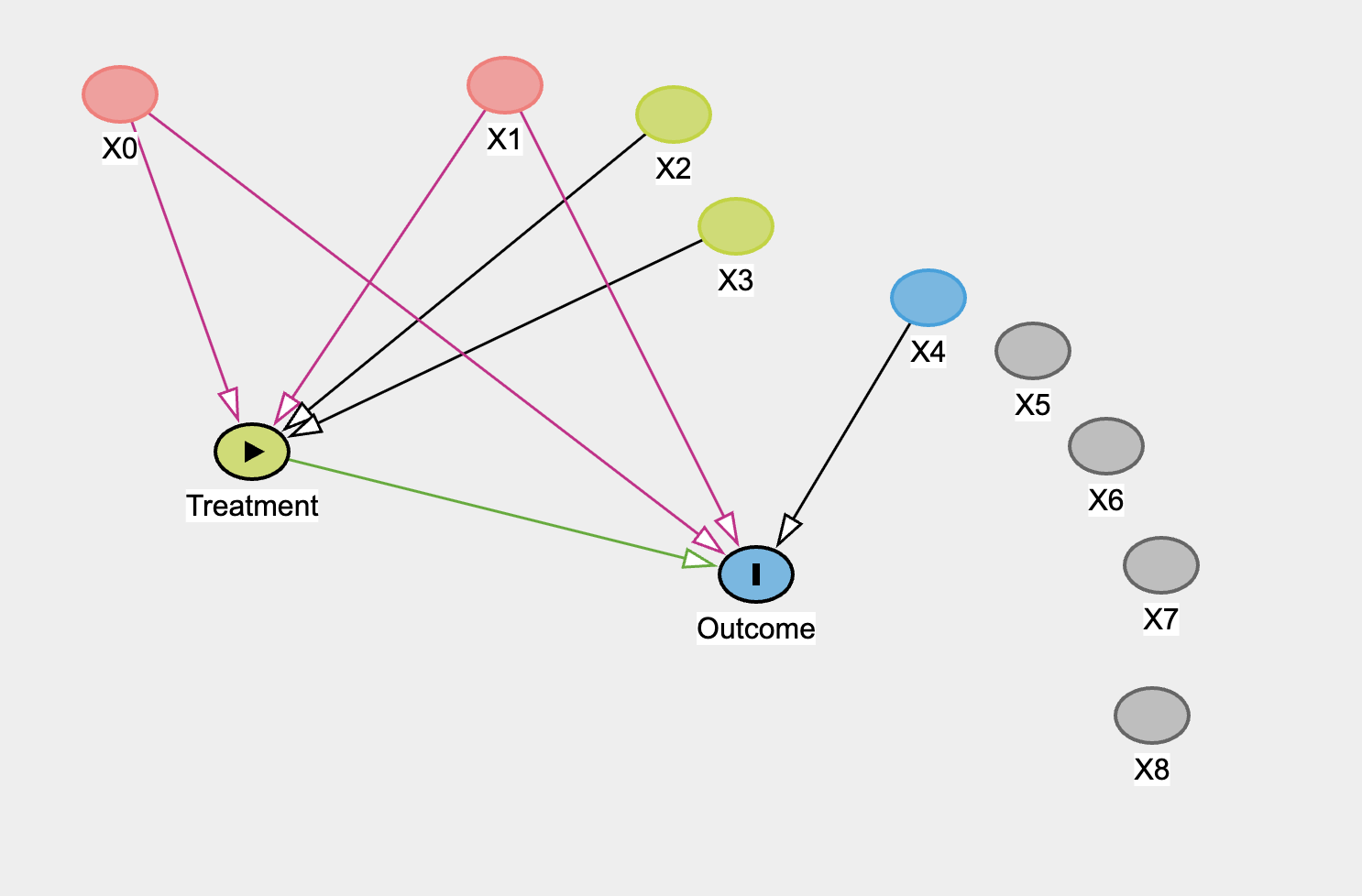
In the simulation code and the diagram above we have allowed the treatment and outcome to be predicted by shared variables X0 and X1. These alone are sufficient to induce confounding into the estimation of the treatment on the outcome. We have also allowed X2, X3 are potentially viable instrumental variables for predicting the outcome purged of the confounding effects of X0 and X1. The rest of the variables are either noise or an independent predictor of the outcome.
Before introducing the Bayesian machinery, it’s worth revisiting what goes wrong with ordinary least squares when the treatment and outcome share unobserved causes. The following code performs a simple sensitivity experiment: we vary the correlation \(\rho\) between the unobserved treatment and outcome errors and examine how the estimated treatment effect changes.
data = simulate_data(n=2500, alpha_true=3, rho=0.6)
features = [col for col in data.columns if "feature" in col]
treatment_effects_binary = []
treatment_effects_continuous = []
df_params = {
"treatment_effects_binary": [],
"treatment_effects_continuous": [],
"rho": [],
}
formula_cont = "Y_cont ~ T_cont + " + " + ".join(features)
formula_bin = "Y_bin ~ T_bin + " + " + ".join(features)
for rho in np.linspace(-1, 1, 10):
data = simulate_data(n=2500, alpha_true=3, rho=rho)
model_cont = smf.ols(formula_cont, data=data).fit()
model_bin = smf.ols(formula_bin, data=data).fit()
df_params["treatment_effects_continuous"].append(model_cont.params["T_cont"])
df_params["treatment_effects_binary"].append(model_bin.params["T_bin"])
df_params["rho"].append(rho)
df_params = pd.DataFrame(df_params)
df_params
| treatment_effects_binary | treatment_effects_continuous | rho | |
|---|---|---|---|
| 0 | -1.201719 | 2.000000 | -1.000000 |
| 1 | -0.351161 | 2.221169 | -0.777778 |
| 2 | 0.766409 | 2.457946 | -0.555556 |
| 3 | 1.644626 | 2.652292 | -0.333333 |
| 4 | 2.712099 | 2.924260 | -0.111111 |
| 5 | 3.441161 | 3.117569 | 0.111111 |
| 6 | 4.347816 | 3.327324 | 0.333333 |
| 7 | 5.243494 | 3.537410 | 0.555556 |
| 8 | 6.258062 | 3.782707 | 0.777778 |
| 9 | 7.248784 | 4.000000 | 1.000000 |
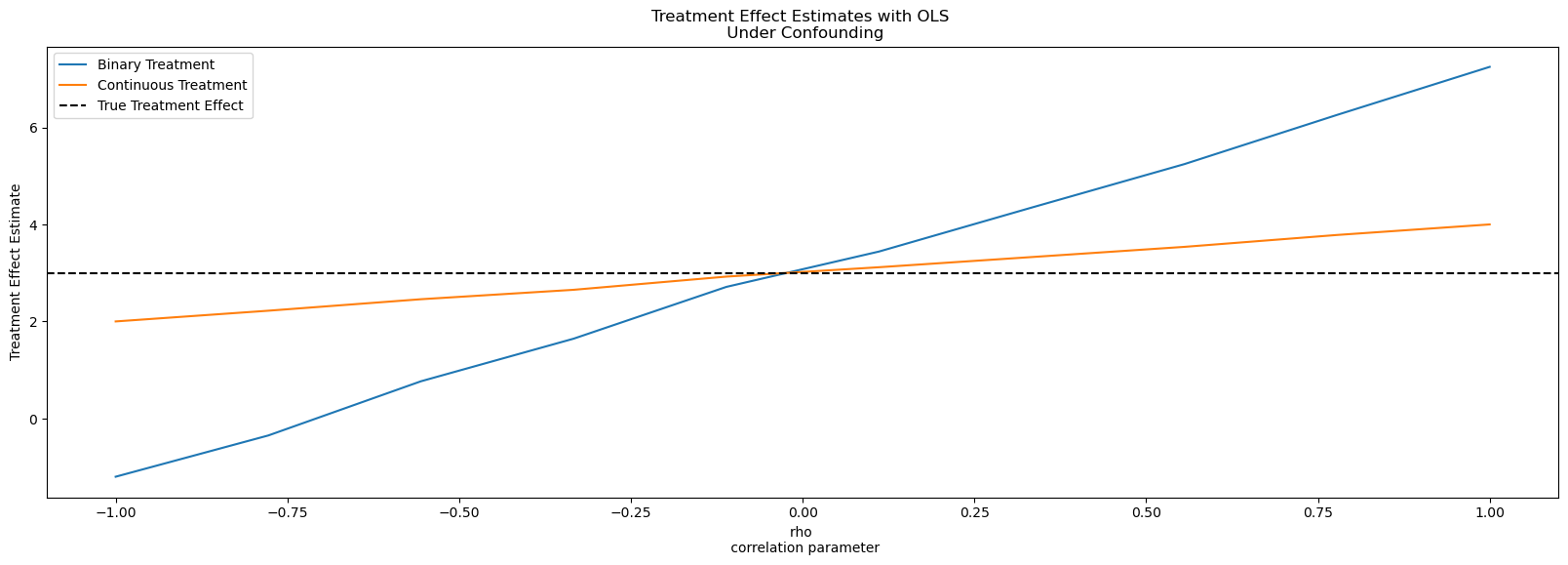
This loop re-simulates the dataset ten times, each with a different value of \(\rho\), ranging from –1 to 1. For each dataset, it fits two OLS regressions: one for the continuous treatment, and another for the binary treatment, both controlling for all observed covariates. The estimated coefficient on the treatment variable T_cont or T_bin—represents what OLS believes to be the causal effect. By collecting these estimates in df_params, we can plot them against the true correlation to see how endogeneity distorts inference.
When \(\rho = 0\) the treatment and outcome errors are independent, and OLS recovers the true causal effect of 3. But as \(\rho\) grows, the estimates drift away from the truth, sometimes dramatically. The direction of bias depends on the sign of the unobserved relationship. If hidden factors push both treatment and outcome the same way, OLS overstates the effect. If they act in opposite directions, it understates it. Even though we’ve controlled for all observed features, the unobserved correlation sneaks bias into our estimates.
fig, ax = plt.subplots(figsize=(20, 6))
ax.plot(
df_params["rho"], df_params["treatment_effects_binary"], label="Binary Treatment"
)
ax.plot(
df_params["rho"],
df_params["treatment_effects_continuous"],
label="Continuous Treatment",
)
ax.axhline(3, linestyle="--", color="k", label="True Treatment Effect")
ax.set_xlabel("rho \n correlation parameter")
ax.set_ylabel("Treatment Effect Estimate")
ax.set_title("Treatment Effect Estimates with OLS \n Under Confounding")
ax.legend();
We now move from diagnosing bias to building a model that can recover causal effects under controlled conditions. To keep things interpretable, we begin with the unconfounded case, where the treatment and outcome share no latent correlation (\(\rho=0\)). This setting lets us isolate what a Bayesian structural model actually does before we expose it to the challenges of endogeneity.
Joint Modelling and Prior Structure#
At the heart of our approach is joint modelling: instead of fitting separate regressions for treatment and outcome, we model them together as draws from a joint multivariate distribution. The treatment equation captures how covariates predict exposure, while the outcome equation captures how both treatment and covariates predict the response. By expressing them jointly, we retain the covariance structure between their errors—an essential ingredient for causal inference once we later introduce confounding.
The model is built using PyMC and organized through the function make_joint_model(). Each version shares the same generative logic but differs in how the priors handle variable selection and identification. We can think of these as different “dial settings” for how strongly the model shrinks irrelevant coefficients or searches for valid instruments. Four prior configurations are explored:
A normal prior, weak regularization with no variable selection. If the model succeeds here, the causal structure is identified through the joint modeling alone.
A spike-and-slab prior, which aggressively prunes away variables unlikely to matter, allowing the model to discover which features are true confounders or instruments.
A horseshoe prior, offering continuous shrinkage that downweights noise while preserving large signals. This is a middle path that downweights weak predictors without forcing them exactly to zero.
An exclusion-restriction prior, explicitly encoding which variables are allowed to influence the treatment but not the outcome, mimicking an instrumental-variable design.
Each prior embodies a different epistemological stance on how much structure the data can learn versus how much the analyst must impose. In the unconfounded case, the treatment and outcome errors are independent, so the joint model effectively decomposes into two connected regressions. The treatment effect \(\alpha\) then captures the causal impact of the treatment on the outcome, and under this setting, its posterior should center around the true value of 3. The goal is not to solve confounding yet but to show that when the world is simple and well-behaved, the Bayesian model recovers the truth just as OLS does—but with richer uncertainty quantification and a coherent probabilistic structure.
The following code defines the model and instantiates it under several prior choices. The model’s graphical representation, produced by pm.model_to_graphviz(), visualizes its structure: covariates feed into both the treatment and the outcome equations, the treatment coefficient \(\alpha\) links them, and the two residuals
\(U\) and \(V\) are connected through a correlation parameter \(\rho\), which we can freely set to zero or more substantive values. These parameterisations offer us a way to derive insight from the structure of the causal system under study.
Fitting the Continuous Treatment Model#
In this next code block we articulate the joint model for the continuous outcome and continuous treatment variable.
coords = {
"beta_outcome": [col for col in data.columns if "feature" in col],
"beta_treatment": [col for col in data.columns if "feature" in col],
"obs": range(data.shape[0]),
"latent": ["U", "V"],
"sigmas_1": ["var_U", "cov_UV"],
"sigmas_2": ["cov_VU", "var_V"],
}
def relaxed_bernoulli(name, p, temperature=0.1, dims=None):
u = pm.Uniform(name + "_u", 0, 1, dims=dims)
logit_p = pt.log(p) - pt.log(1 - p)
return pm.Deterministic(
name, pm.math.sigmoid((logit_p + pt.log(u) - pt.log(1 - u)) / temperature)
)
def make_spike_and_slab_beta():
# RELAXED SPIKE-AND-SLAB PRIORS for aggressive variable selection
pi_O = pm.Beta("pi_O", alpha=2, beta=2)
beta_O_raw = pm.Normal("beta_O_raw", mu=0, sigma=2, dims="beta_outcome")
gamma_O = relaxed_bernoulli("gamma_O", pi_O, temperature=0.1, dims="beta_outcome")
beta_outcome = pm.Deterministic("beta_O", gamma_O * beta_O_raw, dims="beta_outcome")
pi_T = pm.Beta("pi_T", alpha=2, beta=2)
beta_T_raw = pm.Normal("beta_T_raw", mu=0, sigma=2, dims="beta_treatment")
gamma_T = relaxed_bernoulli("gamma_T", pi_T, temperature=0.1, dims="beta_treatment")
beta_treatment = pm.Deterministic(
"beta_T", gamma_T * beta_T_raw, dims="beta_treatment"
)
return beta_outcome, beta_treatment
def make_horseshoe_beta(tau0):
tau_O = pm.HalfStudentT("tau_O", nu=3, sigma=tau0)
# Local shrinkage parameters (one per coefficient)
lambda_O = pm.HalfCauchy("lambda_O", beta=1.0, dims="beta_outcome")
# Regularized horseshoe: c² controls tail behavior
c2_O = pm.InverseGamma("c2_O", alpha=2, beta=2)
lambda_tilde_O = pm.Deterministic(
"lambda_tilde_O",
pm.math.sqrt(c2_O * lambda_O**2 / (c2_O + tau_O**2 * lambda_O**2)),
dims="beta_outcome",
)
# Outcome coefficients with horseshoe prior
beta_O_raw = pm.Normal("beta_O_raw", mu=0, sigma=1, dims="beta_outcome")
beta_outcome = pm.Deterministic(
"beta_O", beta_O_raw * lambda_tilde_O * tau_O, dims="beta_outcome"
)
# Same for treatment equation
tau_T = pm.HalfStudentT("tau_T", nu=3, sigma=tau0)
lambda_T = pm.HalfCauchy("lambda_T", beta=1.0, dims="beta_treatment")
c2_T = pm.InverseGamma("c2_T", alpha=2, beta=2)
lambda_tilde_T = pm.Deterministic(
"lambda_tilde_T",
pm.math.sqrt(c2_T * lambda_T**2 / (c2_T + tau_T**2 * lambda_T**2)),
dims="beta_treatment",
)
beta_T_raw = pm.Normal("beta_T_raw", mu=0, sigma=1, dims="beta_treatment")
beta_treatment = pm.Deterministic(
"beta_T", beta_T_raw * lambda_tilde_T * tau_T, dims="beta_treatment"
)
return beta_outcome, beta_treatment
def make_joint_model(X, Y, T, coords, priors_type="normal", priors={}):
p = X.shape[1]
p0 = 5.0 # pick an expected number of nonzero coeffs
sigma_est = 1.0
tau0 = (p0 / (p - p0)) * (sigma_est / np.sqrt(X.shape[0]))
with pm.Model(coords=coords) as dml_model:
spike_and_slab = priors_type == "spike_and_slab"
horseshoe = priors_type == "horseshoe"
exclusion_restriction = priors_type == "exclusion_restriction"
p = X.shape[1]
if not priors:
priors = {
"rho": [-0.99, 0.99],
}
if spike_and_slab:
beta_outcome, beta_treatment = make_spike_and_slab_beta()
elif horseshoe:
beta_outcome, beta_treatment = make_horseshoe_beta(tau0)
elif exclusion_restriction:
### Ensuring that there is an instruments i.e. predictors of the treatment that
### impact the outcome only through the treatment
beta_outcome = pm.Normal(
"beta_O",
0,
[2.0, 2.0, 0.001, 0.001, 2.0, 2, 2, 2, 2],
dims="beta_outcome",
)
beta_treatment = pm.Normal(
"beta_T",
0,
[2.0, 2.0, 2.0, 2.0, 0.001, 2, 2, 2, 2],
dims="beta_treatment",
)
else:
beta_outcome = pm.Normal("beta_O", 0, 1, dims="beta_outcome")
beta_treatment = pm.Normal("beta_T", 0, 1, dims="beta_treatment")
X_data = pm.Data("X_data", X.values)
observed_data = pm.Data("observed", np.column_stack([Y.values, T.values]))
alpha = pm.Normal("alpha", mu=0, sigma=5)
# Error standard deviations
sigma_U = pm.Exponential("sigma_U", 1.0)
sigma_V = pm.Exponential("sigma_V", 1.0)
# Correlation between errors (confounding parameter)
m = pm.TruncatedNormal(
"m", mu=0, sigma=0.5, lower=priors["rho"][0], upper=priors["rho"][1]
)
s = pm.Beta("s", 2, 2) # scaled half-width
h = pm.Deterministic("h", s * (priors["rho"][1] - pm.math.abs(m)))
lower = pm.Deterministic("lower", m - h)
upper = pm.Deterministic("upper", m + h)
rho = pm.Uniform("rho", lower, upper)
mu_treatment = pm.Deterministic("mu_treatment", X_data @ beta_treatment)
mu_outcome = pm.Deterministic(
"mu_outcome", X_data @ beta_outcome + alpha * mu_treatment
)
var_D = sigma_V**2
var_Y = alpha**2 * sigma_V**2 + sigma_U**2 + 2 * alpha * rho * sigma_U * sigma_V
cov_YD = alpha * sigma_V**2 + rho * sigma_U * sigma_V
# Build 2x2 covariance matrix
cov = pm.math.stack([[var_Y, cov_YD], [cov_YD, var_D]])
# Store as deterministic for inspection
_ = pm.Deterministic("var_Y", var_Y)
_ = pm.Deterministic("var_D", var_D)
_ = pm.Deterministic("cov_YD", cov_YD)
_ = pm.Deterministic("cov_UV", rho * sigma_U * sigma_V)
mu = pm.math.stack([mu_outcome, mu_treatment], axis=1) # shape (n,2)
_ = pm.MvNormal("likelihood", mu=mu, cov=cov, observed=observed_data)
return dml_model
def make_continuous_models(data):
X = data[[col for col in data.columns if "feature" in col]]
Y = data["Y_cont"]
T = data["T_cont"]
coords = {
"beta_outcome": [col for col in data.columns if "feature" in col],
"beta_treatment": [col for col in data.columns if "feature" in col],
"obs": range(data.shape[0]),
}
spike_and_slab = make_joint_model(X, Y, T, coords, priors_type="spike_and_slab")
horseshoe = make_joint_model(X, Y, T, coords, priors_type="horseshoe")
excl = make_joint_model(X, Y, T, coords, priors_type="exclusion_restriction")
normal = make_joint_model(X, Y, T, coords, priors_type="normal")
tight_rho = make_joint_model(
X, Y, T, coords, priors_type="normal", priors={"rho": [0.4, 0.99]}
)
tight_rho_s_s = make_joint_model(
X, Y, T, coords, priors_type="spike_and_slab", priors={"rho": [0.4, 0.99]}
)
models = {
"spike_and_slab": spike_and_slab,
"horseshoe": horseshoe,
"exclusion": excl,
"normal": normal,
"tight_rho": tight_rho,
"tight_rho_s_s": tight_rho_s_s,
}
return models
data_confounded = simulate_data(n=2500, alpha_true=3, rho=0.6)
data_unconfounded = simulate_data(n=2500, alpha_true=3, rho=0)
models_confounded = make_continuous_models(data_confounded)
models_unconfounded = make_continuous_models(data_unconfounded)
pm.model_to_graphviz(models_confounded["spike_and_slab"])

This section orchestrates the fitting and sampling workflow for the suite of Bayesian models defined earlier. Having specified several variants of the joint outcome–treatment model—each differing only in its prior structure or treatment of the correlation parameter \(\rho\)—we now turn to posterior inference.
Various Model Specifications#
The functions sample_model(), and fit_models() provide a compact, repeatable sampling pipeline. Within the model context, it first draws from the prior predictive distribution, capturing what the model believes about the data before seeing any observations. These are comparable across each of models specified.
We’re moving from describing how the data are assumed to arise, to actually learning from the simulated observations. This is the backwards inference step. The output idata_unconfounded contains all posterior draws, prior predictive samples, and posterior predictive simulations for every model variant under the assumption of no confounding. This will allow us to compare the inferences achieved under each setting. To gauge which are the most plausible parameterisations of the world-state conditioned on the data and our model-specification.
def sample_model(model, fit_kwargs):
with model:
idata = pm.sample_prior_predictive()
idata.extend(
pm.sample(
draws=1000,
tune=2000,
target_accept=0.95,
**fit_kwargs,
idata_kwargs={"log_likelihood": True},
)
)
idata.extend(pm.sample_posterior_predictive(idata))
return idata
fit_kwargs = {}
def fit_models(fit_kwargs, models):
idata_spike_and_slab = sample_model(models["spike_and_slab"], fit_kwargs=fit_kwargs)
idata_horseshoe = sample_model(models["horseshoe"], fit_kwargs=fit_kwargs)
idata_excl = sample_model(models["exclusion"], fit_kwargs=fit_kwargs)
idata_normal = sample_model(models["normal"], fit_kwargs=fit_kwargs)
idata_normal_rho_tight = sample_model(models["tight_rho"], fit_kwargs=fit_kwargs)
idata_rho_tight_s_s = sample_model(models["tight_rho_s_s"], fit_kwargs=fit_kwargs)
idatas = {
"spike_and_slab": idata_spike_and_slab,
"horseshoe": idata_horseshoe,
"exclusion": idata_excl,
"normal": idata_normal,
"rho_tight": idata_normal_rho_tight,
"rho_tight_spike_slab": idata_rho_tight_s_s,
}
return idatas
idata_unconfounded = fit_models(fit_kwargs, models_unconfounded)
Show code cell output
Sampling: [alpha, beta_O_raw, beta_T_raw, gamma_O_u, gamma_T_u, likelihood, m, pi_O, pi_T, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [pi_O, beta_O_raw, gamma_O_u, pi_T, beta_T_raw, gamma_T_u, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 375 seconds.
There were 3 divergences after tuning. Increase `target_accept` or reparameterize.
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [likelihood]
Sampling: [alpha, beta_O_raw, beta_T_raw, c2_O, c2_T, lambda_O, lambda_T, likelihood, m, rho, s, sigma_U, sigma_V, tau_O, tau_T]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [tau_O, lambda_O, c2_O, beta_O_raw, tau_T, lambda_T, c2_T, beta_T_raw, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 150 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [likelihood]
Sampling: [alpha, beta_O, beta_T, likelihood, m, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_O, beta_T, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 89 seconds.
There was 1 divergence after tuning. Increase `target_accept` or reparameterize.
Sampling: [likelihood]
Sampling: [alpha, beta_O, beta_T, likelihood, m, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_O, beta_T, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 116 seconds.
There was 1 divergence after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
Sampling: [likelihood]
Sampling: [alpha, beta_O, beta_T, likelihood, m, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_O, beta_T, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 86 seconds.
Sampling: [likelihood]
Sampling: [alpha, beta_O_raw, beta_T_raw, gamma_O_u, gamma_T_u, likelihood, m, pi_O, pi_T, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [pi_O, beta_O_raw, gamma_O_u, pi_T, beta_T_raw, gamma_T_u, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 392 seconds.
There were 4 divergences after tuning. Increase `target_accept` or reparameterize.
Sampling: [likelihood]
Before examining how different priors shape inference, it’s useful to clarify what our models are actually estimating. Each specification—spike-and-slab, horseshoe, exclusion restriction, and the others—ultimately targets the same estimand: the slope \(\alpha\) that captures how changes in the continuous treatment \(T\) shift the expected outcome \(Y\). In this setup, \(\alpha\) functions as a regression coefficient within the structural equation of our joint model.
In econometric terms, what we’ve done so far sits squarely within the structural modelling tradition. We’ve written down a joint model for both the treatment and the outcome, specified their stochastic dependencies explicitly, and interpreted the slope \(\alpha\) as a structural parameter — a feature of the data-generating process itself. This parameter has a causal meaning only insofar as the model is correctly specified: if the structural form reflects how the world actually works, \(\alpha\) recovers the true causal effect. By contrast, reduced-form econometrics focuses less on modelling the underlying mechanisms and more on identifying causal effects through observable associations research design — instrumental variables, difference-in-differences, or randomization. Reduced-form approaches avoid the need to specify the joint distribution of unobservables but often sacrifice interpretability: they estimate relationships that are valid for specific interventions or designs, not necessarily structural primitives.
Comparing Treatment Estimates#
The comparison of models is a form of robustness checks. We want to inspect how consistent our parameter estimates are across different model specifications. Here we see how the strongly informative priors on \(\rho\) bias the treatment effect estimate.
Show code cell source
ax = az.plot_forest(
[
idata_unconfounded["spike_and_slab"],
idata_unconfounded["horseshoe"],
idata_unconfounded["exclusion"],
idata_unconfounded["normal"],
idata_unconfounded["rho_tight"],
idata_unconfounded["rho_tight_spike_slab"],
],
var_names=["alpha", "rho", "beta_O", "beta_T"],
combined=True,
model_names=[
"spike_slab",
"horse shoe",
"exclusion_restriction",
"normal",
"tight_rho",
"tight_rho_spike_slab",
],
figsize=(20, 15),
)
ax[0].axvline(3, linestyle="--", color="k")
ax[0].set_title(
"Comparing Parameter Estimates across Model Specifications", fontsize=15
);
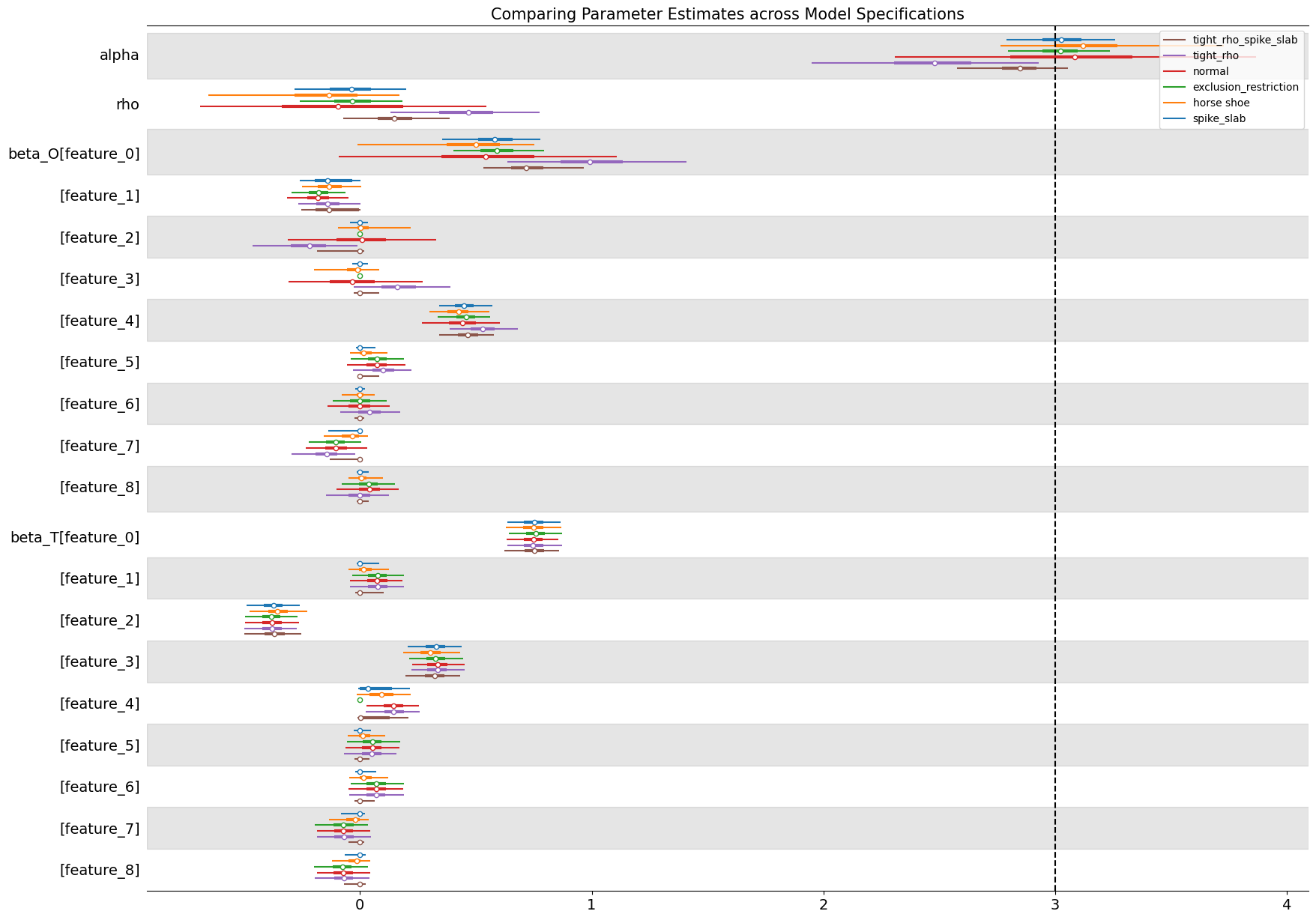
In the plot we can see that the majority of models accurately estimate the true treatment effect \(\alpha\) except in the cases where we have explicitly placed an opinionated prior on the \(\rho\) parameter in the model. These priors pull the \(\alpha\) estimate away from the true data generating process. The variable selection priors considerably shrink the uncertainty in the treatment estimates seemingly picking out the implicit instrument structure aping the application of instrumental variables.
Our Bayesian setup here is intentionally structural. We specify how both treatment and outcome arise from common covariates and latent confounding structures. However, the boundary between structural and reduced-form reasoning becomes fluid when we begin to treat latent variables or exclusion restrictions as data-driven “instruments.” In that sense, the structural Bayesian approach can emulate reduced-form logic within a generative model — an idea we’ll develop further when we move from unconfounded to confounded data and later when we impute potential outcomes directly.
But for now let’s continue to examine the relationships between these structural parameters.
Show code cell source
fig, axs = plt.subplots(2, 3, figsize=(15, 8), sharex=True, sharey=True)
axs = axs.flatten()
az.plot_pair(
idata_unconfounded["spike_and_slab"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[0],
)
az.plot_pair(
idata_unconfounded["horseshoe"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[1],
)
az.plot_pair(
idata_unconfounded["exclusion"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[2],
)
az.plot_pair(
idata_unconfounded["normal"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[3],
)
az.plot_pair(
idata_unconfounded["rho_tight"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[4],
)
az.plot_pair(
idata_unconfounded["rho_tight_spike_slab"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[5],
)
for ax, m in zip(
axs,
[
"spike_slab",
"horse shoe",
"exclusion_restriction",
"normal",
"tight_rho",
"tight_rho_spike_slab",
],
):
ax.axvline(3, linestyle="--", color="k", label="True Treatment Effect")
ax.axhline(0, linestyle="--", color="red", label="True rho")
ax.set_title(f"Posterior Relationship {m}")
ax.legend(loc="lower left")
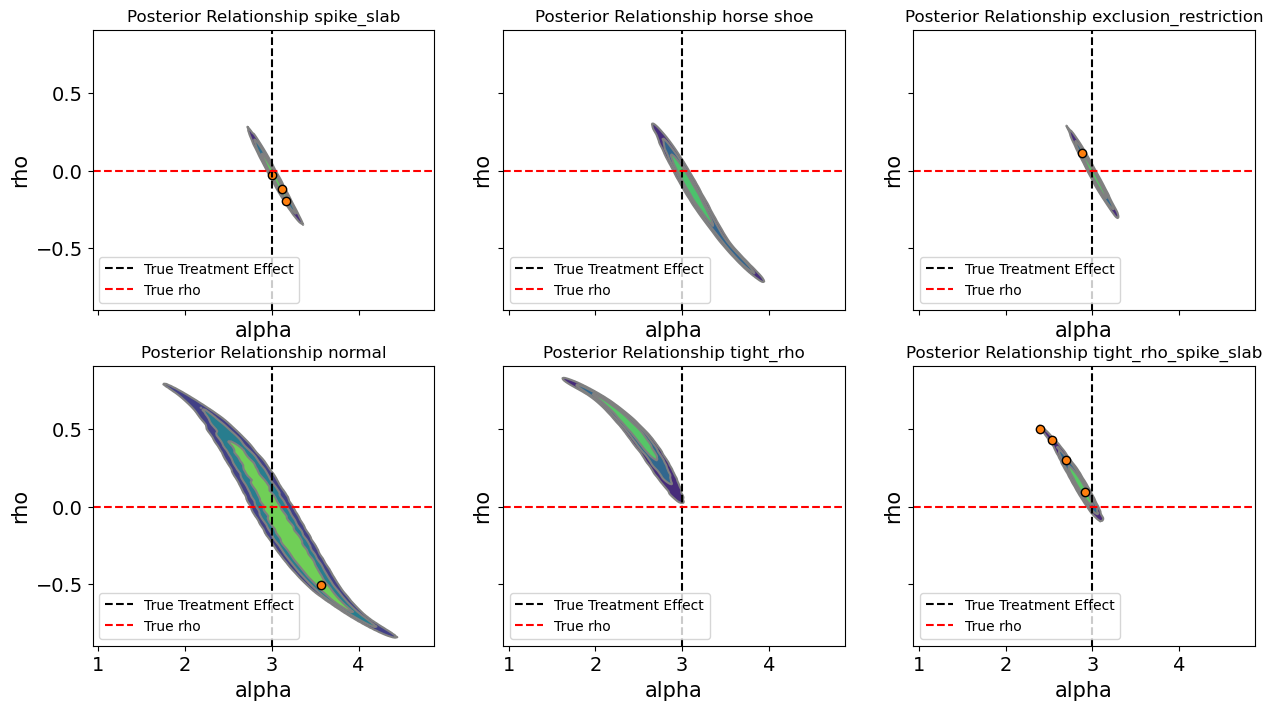
Up to this point, we have looked at posterior summaries of individual parameters, such as the treatment effect \(\alpha\) or the correlation \(\rho\). While these marginal summaries are useful, they can obscure important interactions between parameters. In a structural model, the slope \(\alpha\) does not exist in isolation. Its interpretation depends on the joint distribution of the latent errors and the covariates that generate the treatment and outcome.
The pairwise posterior plots below examine the joint distributions of \(\alpha\) and \(\rho\) and across different prior specifications. Each subplot shows the density of the posterior draws, highlighting how the inferred treatment effect co-varies with the estimated correlation between latent errors. The dashed vertical line marks the true causal effect, and the horizontal line shows the true values.
By inspecting these joint distributions, we gain several insights: aggressive priors on \(\rho\) can pull the posterior of away from zero, which in turn shifts the distribution of the treatment effect estimate. But additionlly variable selection schemes like the spike-and-slab or horseshoe can significantly reduce uncertainty in the estimation of both \(\rho\) and \(\alpha\). This illustrates the trade-off between automated variable selection, prior specification.
Show code cell source
df_params = pd.concat(
{
"rho_tight": az.summary(
idata_unconfounded["rho_tight"], var_names=["alpha", "rho"]
),
"normal": az.summary(idata_unconfounded["normal"], var_names=["alpha", "rho"]),
"spike_slab": az.summary(
idata_unconfounded["spike_and_slab"], var_names=["alpha", "rho"]
),
"horseshoe": az.summary(
idata_unconfounded["horseshoe"], var_names=["alpha", "rho"]
),
"exclusion_restriction": az.summary(
idata_unconfounded["exclusion"], var_names=["alpha", "rho"]
),
"tight_rho_spike_slab": az.summary(
idata_unconfounded["rho_tight_spike_slab"], var_names=["alpha", "rho"]
),
}
)
df_params
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | ||
|---|---|---|---|---|---|---|---|---|---|---|
| rho_tight | alpha | 2.454 | 0.265 | 1.950 | 2.929 | 0.010 | 0.007 | 809.0 | 1456.0 | 1.01 |
| rho | 0.454 | 0.173 | 0.133 | 0.774 | 0.006 | 0.003 | 796.0 | 1468.0 | 1.01 | |
| normal | alpha | 3.079 | 0.417 | 2.308 | 3.866 | 0.021 | 0.012 | 400.0 | 868.0 | 1.01 |
| rho | -0.075 | 0.347 | -0.690 | 0.546 | 0.017 | 0.007 | 401.0 | 858.0 | 1.01 | |
| spike_slab | alpha | 3.029 | 0.129 | 2.790 | 3.258 | 0.003 | 0.003 | 1514.0 | 1345.0 | 1.00 |
| rho | -0.040 | 0.130 | -0.282 | 0.198 | 0.003 | 0.002 | 1515.0 | 1393.0 | 1.00 | |
| horseshoe | alpha | 3.167 | 0.254 | 2.763 | 3.728 | 0.016 | 0.016 | 395.0 | 330.0 | 1.01 |
| rho | -0.161 | 0.219 | -0.653 | 0.169 | 0.012 | 0.009 | 395.0 | 348.0 | 1.01 | |
| exclusion_restriction | alpha | 3.018 | 0.116 | 2.797 | 3.237 | 0.003 | 0.002 | 1804.0 | 1915.0 | 1.00 |
| rho | -0.030 | 0.118 | -0.260 | 0.185 | 0.003 | 0.002 | 1847.0 | 1832.0 | 1.00 | |
| tight_rho_spike_slab | alpha | 2.829 | 0.141 | 2.577 | 3.054 | 0.007 | 0.012 | 779.0 | 411.0 | 1.00 |
| rho | 0.161 | 0.126 | -0.072 | 0.386 | 0.006 | 0.007 | 800.0 | 426.0 | 1.00 |
Similarly we can compare the models on holistic performance measures like leave-one-out cross validation. Note however, that the primary purpose here is to showcase sensitivity of the parameter of interest to model specifications. We’re not necessarily seeking to enshrine one model as the best.
compare_df = az.compare(idata_unconfounded)
az.plot_compare(compare_df, figsize=(15, 7));
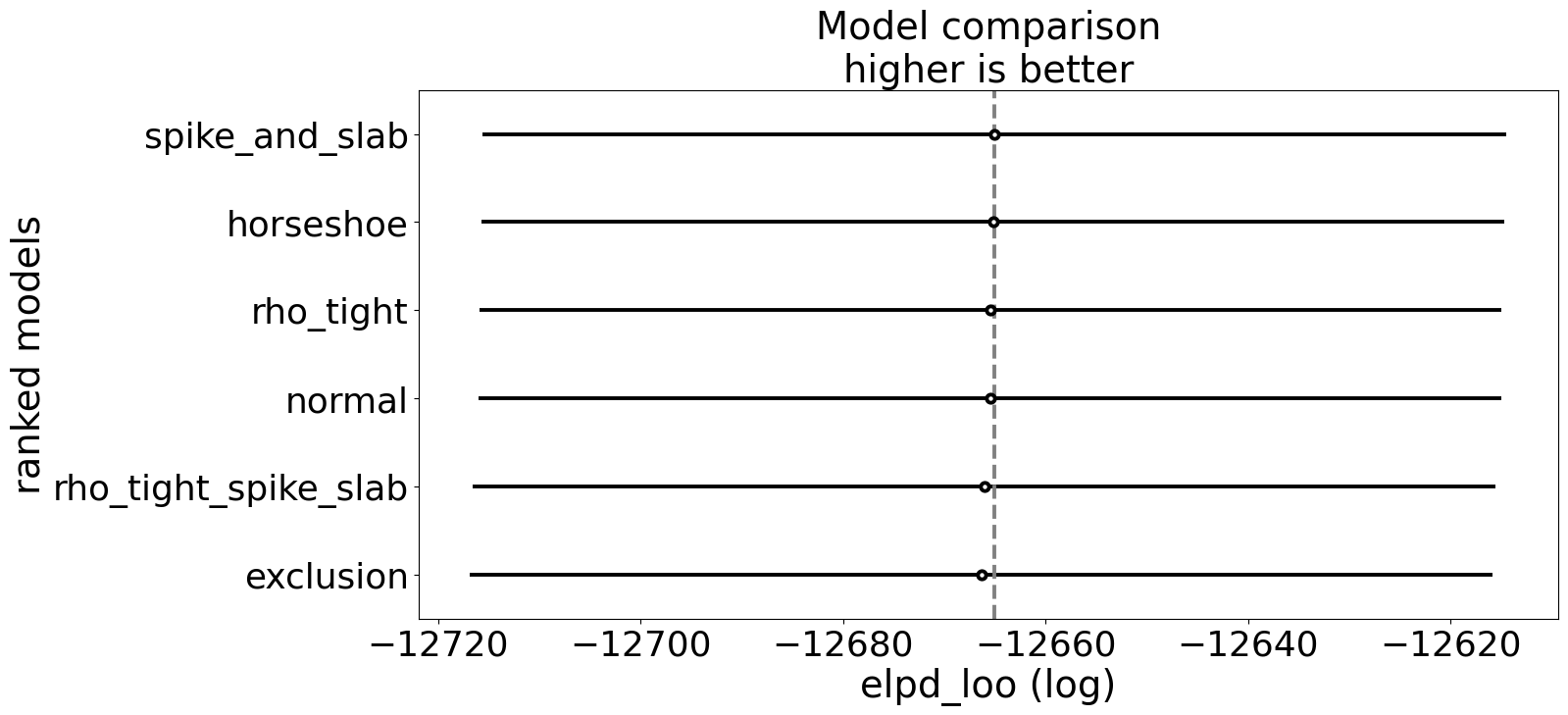
The tables highlights the model’s sensitivity to priors. Sparse priors, like spike-and-slab and horseshoe, can slightly shrink coefficients and influence the posterior spread, particularly for \(\rho\), but strong priors directly on \(\rho\) can negatively impact the estimation routine. especially when there is no true correlation. This is not a flaw. It is a feature. In practical settings, treatments and outcomes are often correlated due to unobserved confounding, measurement error, or endogenous selection. For example, in a health economics study, patients who choose a particular therapy may do so because of unobserved health determinents that also influence recovery—such as risk tolerance, underlying severity, or access to informal support. In labor economics, higher wages may appear to cause greater job satisfaction, but workers who are more motivated or more socially connected might self-select into higher-paying jobs, creating correlation between the unobserved determinants of treatment and outcome By exposing the model to different prior assumptions, we can probe how strong beliefs about sparsity or instrument validity propagate into causal estimates.
In other words, prior sensitivity is a diagnostic tool as much as a regularization mechanism. When \(\rho\) is expected to be nonzero i.e. in observational studies with likely latent confounding, then explicitly modelling its distribution becomes crucial. The unconfounded case, therefore, serves as a baseline: it confirms that our joint Bayesian model can recover true parameters when the world is simple, while setting the stage for exploring more realistic, confounded scenarios where these structural dependencies must be handled carefully.
The Confounded Case#
While the unconfounded case provides a useful benchmark, most real-world observational studies involve some degree of endogenous treatment assignment. In our simulations, this occurs when the residuals of the treatment and outcome equations are correlated. This demonstrates that controlling only for measured variables is insufficient when unobserved confounders influence both treatment and outcome.
The Bayesian joint model provides a principled solution. By explicitly modelling the correlation between treatment and outcome residuals, the framework can adjust for latent confounding while still estimating the causal slope \(\alpha\). Moreover, flexible priors such as spike-and-slab and horseshoe allow the model to automatically discover potential instruments i.e. covariates that predict the treatment but not the outcome. The theory is that the instrument structure if it holds in the world is also the one which best calibrates our parameters. These instruments help disentangle the structural effect of the treatment from latent correlations, improving identification.
By setting \(\rho\) = 0.6 we simulate a moderate level of confounding—similar in spirit to cases where unmeasured preferences, abilities, or environmental factors drive both exposure and response. Conceptually, this setup mimics situations such as:
More health-conscious individuals being both more likely to adopt a preventive therapy and more likely to recover quickly.
High-income households being more likely to invest in cleaner technologies and experience better environmental outcomes.
Firms with stronger internal capabilities both adopting new management practices and achieving higher productivity.
Under such conditions, simple regression cannot disentangle correlation from causation, as the treatment is no longer independent of the unobserved outcome drivers.
idata_confounded = fit_models(fit_kwargs, models_confounded)
Show code cell output
Sampling: [alpha, beta_O_raw, beta_T_raw, gamma_O_u, gamma_T_u, likelihood, m, pi_O, pi_T, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [pi_O, beta_O_raw, gamma_O_u, pi_T, beta_T_raw, gamma_T_u, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 484 seconds.
There were 4 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [likelihood]
Sampling: [alpha, beta_O_raw, beta_T_raw, c2_O, c2_T, lambda_O, lambda_T, likelihood, m, rho, s, sigma_U, sigma_V, tau_O, tau_T]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [tau_O, lambda_O, c2_O, beta_O_raw, tau_T, lambda_T, c2_T, beta_T_raw, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 259 seconds.
There were 3 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
Sampling: [likelihood]
Sampling: [alpha, beta_O, beta_T, likelihood, m, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_O, beta_T, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 142 seconds.
There were 2 divergences after tuning. Increase `target_accept` or reparameterize.
Sampling: [likelihood]
Sampling: [alpha, beta_O, beta_T, likelihood, m, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_O, beta_T, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 148 seconds.
There were 4 divergences after tuning. Increase `target_accept` or reparameterize.
Sampling: [likelihood]
Sampling: [alpha, beta_O, beta_T, likelihood, m, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_O, beta_T, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 96 seconds.
Sampling: [likelihood]
Sampling: [alpha, beta_O_raw, beta_T_raw, gamma_O_u, gamma_T_u, likelihood, m, pi_O, pi_T, rho, s, sigma_U, sigma_V]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [pi_O, beta_O_raw, gamma_O_u, pi_T, beta_T_raw, gamma_T_u, alpha, sigma_U, sigma_V, m, s, rho]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 454 seconds.
There were 11 divergences after tuning. Increase `target_accept` or reparameterize.
Sampling: [likelihood]
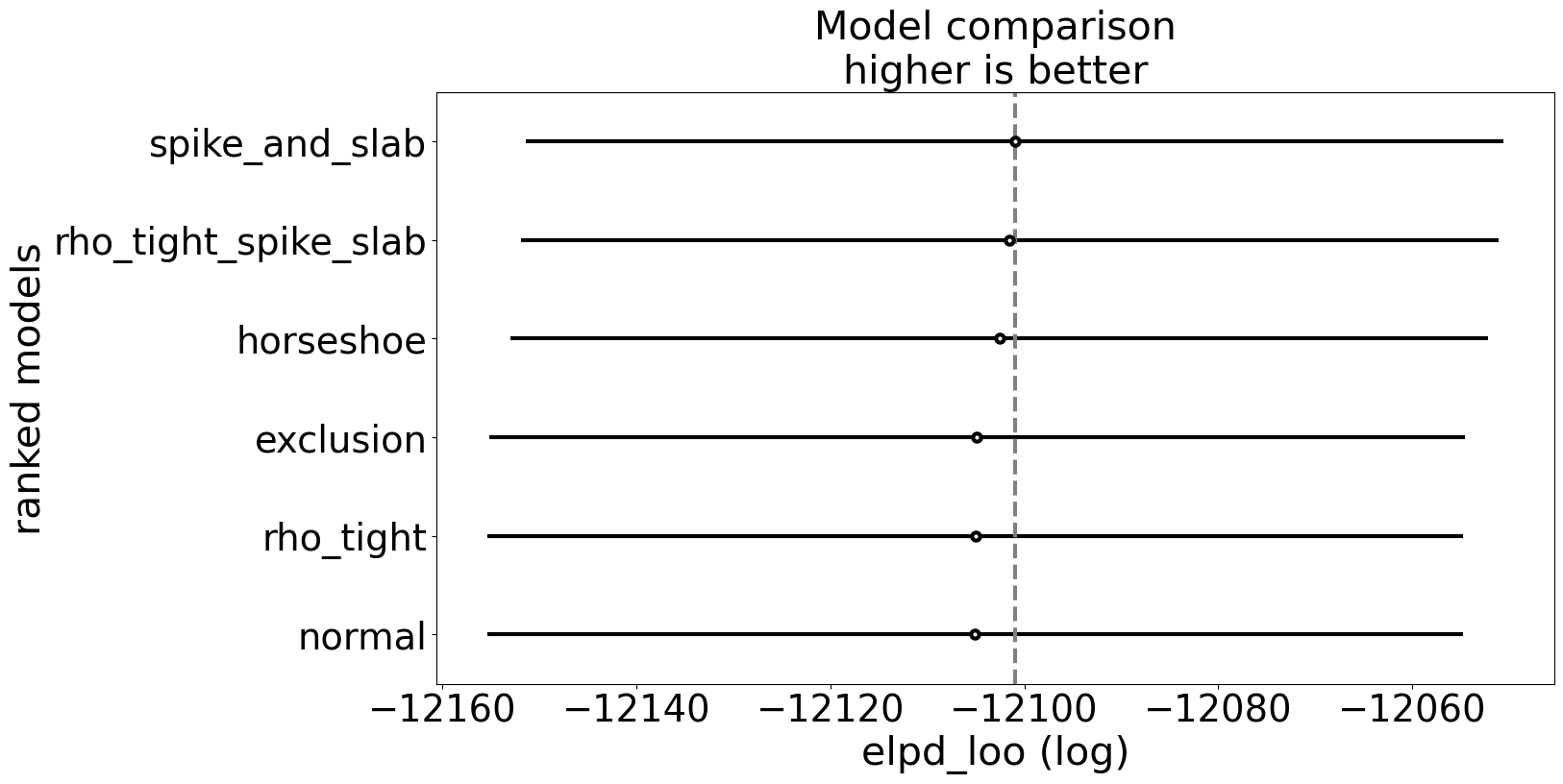
We can again compare these models on predictive performance measures, but the real focus is on the success of the causal identification within these model specifications. The performance metrics also highlight that they’re broadly similar models. Another way to see this is that grading models on predictive performance does not ensure that the model correctly identifies the causal mechanism. Indistinguishable, predictive performance does not ensure mechanistic accuracy.
compare_df = az.compare(idata_confounded)
az.plot_compare(compare_df, figsize=(15, 8));
Comparing Treatment Estimates#
The forest plot below compares posterior estimates of the treatment effect (\(\alpha\)) and the confounding correlation (\(\rho\)) across model specifications when \(\rho = .6\) in the data-generating process. The baseline normal model (which places diffuse priors on all parameters) clearly reflects the presence of endogeneity. Its posterior mean for \(\alpha\) is biased upward relative to the true value of 3, and the estimated \(\rho\) is positive, confirming that the model detects correlation between treatment and outcome disturbances. This behaviour mirrors the familiar bias of OLS under confounding: without structural constraints or informative priors, the model attributes part of the outcome variation caused by unobserved factors to the treatment itself. This inflates and corrupts our treatment effect estimate.
Show code cell source
ax = az.plot_forest(
[
idata_confounded["spike_and_slab"],
idata_confounded["horseshoe"],
idata_confounded["exclusion"],
idata_confounded["normal"],
idata_confounded["rho_tight"],
idata_confounded["rho_tight_spike_slab"],
],
var_names=["alpha", "rho", "beta_O", "beta_T"],
combined=True,
model_names=[
"spike_slab",
"horse shoe",
"exclusion_restriction",
"normal",
"tight_rho",
"tight_rho_spike_slab",
],
figsize=(20, 15),
)
ax[0].axvline(3, linestyle="--", color="k")
ax[0].set_title(
"Comparing Parameter Estimates across Model Specifications", fontsize=15
);
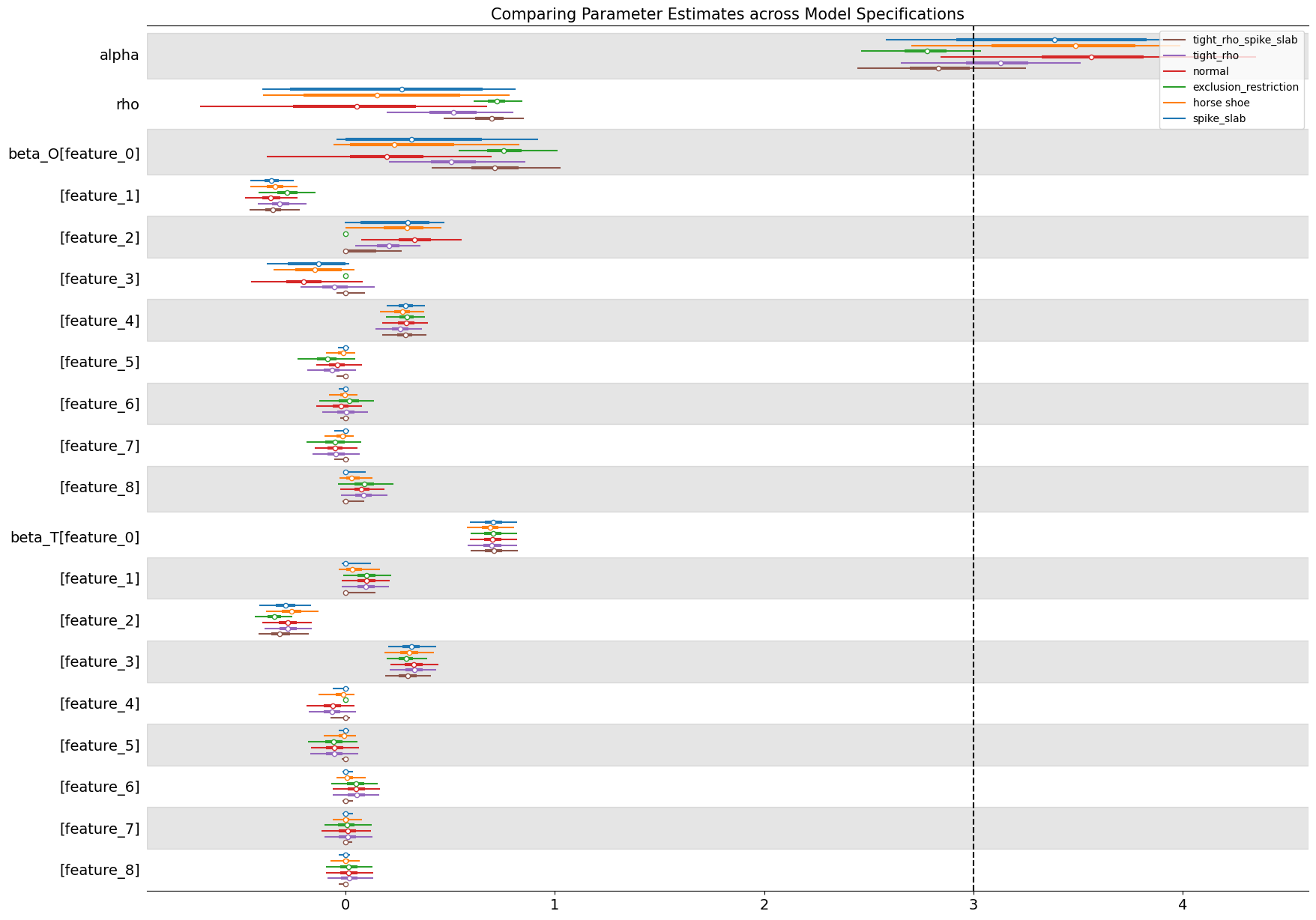
By contrast, models that introduce structure through priors—either by tightening the prior range on \(\rho\) or imposing shrinkage on the regression coefficients—perform noticeably better. The tight-\(\rho\) models regularize the latent correlation, effectively limiting the extent to which endogeneity can distort inference, while spike-and-slab and horseshoe priors perform selective shrinkage on the covariates, allowing the model to emphasize variables that genuinely predict the treatment. This helps isolate more valid “instrument-like” components of variation, pulling the posterior of \(\alpha\) closer to the true causal effect.
The exclusion-restriction specification, which enforces prior beliefs about which covariates affect only the treatment or only the outcome, performs well too. The imposed restrictions recover both the correct treatment effect and a tight estimate of residual correlation. It may be wishful thinking that this precise instrument structure is available to an analyst in the applied setting, but instrument variable designs and their imposed exclusion restrictions should be motivated by theory. Where that theory is plausible we can hope for such precise estimates.
Together, these results illustrate the power of Bayesian joint modelling: even in the presence of confounding, appropriate prior structure enables partial recovery of causal effects. Importantly, the priors do not simply “fix” the bias—they make explicit the trade-offs between flexibility and identification. This transparency is one of the key advantages of Bayesian causal inference over traditional reduced-form methods.
We can see similar patterns in the below pair plots
Show code cell source
fig, axs = plt.subplots(2, 3, figsize=(15, 8), sharex=True, sharey=True)
axs = axs.flatten()
az.plot_pair(
idata_confounded["spike_and_slab"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[0],
)
az.plot_pair(
idata_confounded["horseshoe"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[1],
)
az.plot_pair(
idata_confounded["exclusion"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[2],
)
az.plot_pair(
idata_confounded["normal"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[3],
)
az.plot_pair(
idata_confounded["rho_tight"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[4],
)
az.plot_pair(
idata_confounded["rho_tight_spike_slab"],
var_names=["alpha", "rho"],
kind="kde",
divergences=True,
ax=axs[5],
)
for ax, m in zip(
axs,
[
"spike_slab",
"horse shoe",
"exclusion_restriction",
"normal",
"tight_rho",
"tight_rho_spike_slab",
],
):
ax.axvline(3, linestyle="--", color="k", label="True Treatment Effect")
ax.axhline(0.6, linestyle="--", color="red", label="True rho")
ax.set_title(f"Posterior Relationship {m}")
ax.legend(loc="lower left")
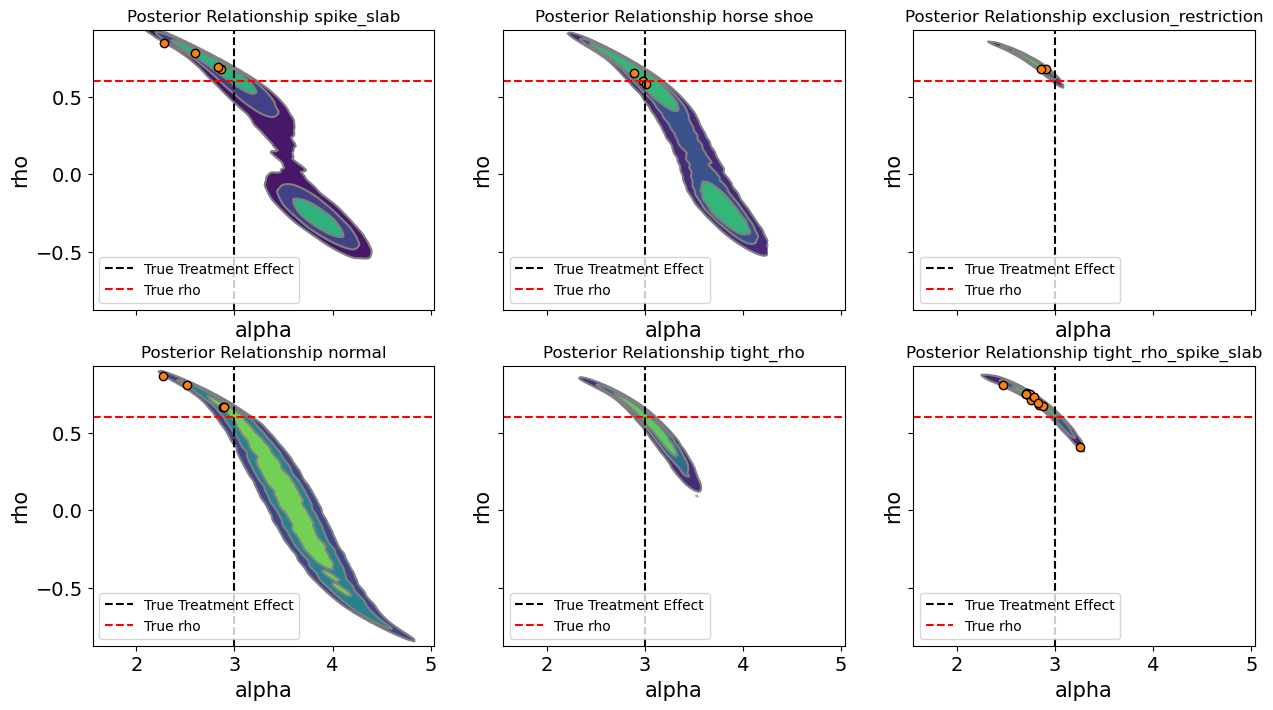
Each panel displays the joint posterior density between these two parameters for a given model specification.
In the baseline normal model, the posteriors of \(\alpha\) and \(\rho\) exhibit a strong negative association: as the inferred residual correlation decreases, the estimated treatment effect increases. This pattern is characteristic of endogeneity. Part of the treatment’s apparent effect on the outcome is actually explained by unobserved factors that simultaneously drive both. The normal model correctly detects confounding but cannot disentangle its consequences without additional structure, leaving the treatment effect biased.
One other feature evident from the spike and slab and horseshoe models is that the posterior distribution is somewhat bi-modal. The evidence pulls in two ways. There is not sufficient evidence in the data alone for the model to decisively characterise the \(\rho\) parameter and this induces a schizophrenic posterior distribution in the \(\alpha\) values estimated with these models. In other words, the posterior appears bi-modal. There are multiple centres of mass in the probability distribution representing a kind of indecision or oscillation between two views of the world.
Introducing tight-\(\rho\) priors fundamentally changes this relationship. By constraining the allowable range of to moderate values, we effectively impose an analyst’s belief that the degree of confounding, while nonzero, is not overwhelming. This acts as a form of structural regularization: the posterior of \(\alpha\) stabilizes around the true causal effect. In practice, this mirrors what applied analysts often do implicitly. By imposing a weakly informative prior we anchor the model with plausible bounds on endogeneity rather than assuming perfect exogeneity or unbounded correlation. The preference for weakly informative priors here improves the sampling geometry but also clarifies the theoretical position of the analyst.
Show code cell source
df_params = pd.concat(
{
"rho_tight": az.summary(
idata_confounded["rho_tight"], var_names=["alpha", "rho"]
),
"normal": az.summary(idata_confounded["normal"], var_names=["alpha", "rho"]),
"spike_slab": az.summary(
idata_confounded["spike_and_slab"], var_names=["alpha", "rho"]
),
"horseshoe": az.summary(
idata_confounded["horseshoe"], var_names=["alpha", "rho"]
),
"exclusion_restriction": az.summary(
idata_confounded["exclusion"], var_names=["alpha", "rho"]
),
"tight_rho_spike_slab": az.summary(
idata_confounded["rho_tight_spike_slab"], var_names=["alpha", "rho"]
),
}
)
df_params
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | ||
|---|---|---|---|---|---|---|---|---|---|---|
| rho_tight | alpha | 3.098 | 0.237 | 2.654 | 3.511 | 0.008 | 0.008 | 949.0 | 861.0 | 1.00 |
| rho | 0.508 | 0.164 | 0.198 | 0.802 | 0.005 | 0.003 | 954.0 | 750.0 | 1.00 | |
| normal | alpha | 3.560 | 0.400 | 2.841 | 4.350 | 0.018 | 0.014 | 511.0 | 522.0 | 1.01 |
| rho | 0.042 | 0.386 | -0.695 | 0.678 | 0.017 | 0.008 | 511.0 | 563.0 | 1.01 | |
| spike_slab | alpha | 3.362 | 0.491 | 2.581 | 3.984 | 0.047 | 0.007 | 139.0 | 1001.0 | 1.05 |
| rho | 0.193 | 0.460 | -0.398 | 0.812 | 0.045 | 0.003 | 138.0 | 926.0 | 1.05 | |
| horseshoe | alpha | 3.414 | 0.405 | 2.702 | 3.989 | 0.021 | 0.008 | 427.0 | 1169.0 | 1.01 |
| rho | 0.169 | 0.391 | -0.394 | 0.784 | 0.020 | 0.004 | 427.0 | 1101.0 | 1.01 | |
| exclusion_restriction | alpha | 2.764 | 0.153 | 2.464 | 3.036 | 0.005 | 0.003 | 1168.0 | 1351.0 | 1.00 |
| rho | 0.718 | 0.062 | 0.611 | 0.844 | 0.002 | 0.001 | 1181.0 | 1478.0 | 1.00 | |
| tight_rho_spike_slab | alpha | 2.829 | 0.219 | 2.446 | 3.251 | 0.007 | 0.005 | 915.0 | 1419.0 | 1.00 |
| rho | 0.678 | 0.107 | 0.469 | 0.851 | 0.004 | 0.002 | 923.0 | 1483.0 | 1.00 |
Across all specifications, the diagnostics tell a consistent story: effective sample sizes are high, rhat values hover near 1.00, and divergent transitions are minimal or absent. These are healthy traces, suggesting that the posterior geometries are well-explored and that the models are numerically stable under their respective prior assumptions.
Causal Identification and Variable Selection#
Before continuing to the binary case it’s worth diving into the role of priors in these structural causal models. Both spike and slab and horseshoe priors were designed to perform automatic variable selection. The spike-and-slab via a latent mixture of near-zero and freely estimated components, and the horseshoe through continuous shrinkage that allows strong predictors to survive while damping weak or spurious ones. Ultimately these priors determine the multiplicative weights of the \(\beta\) coefficients in the model. By placing these variable selection priors on the weights, they are calibrated against the data so as to zero-out those variables that are not required. For a more thorough discussion of automated variable selection using priors we recommend Kaplan [2024] and the pymc discourse site.
Plotting these posteriors vividly illustrates their behavior more clearly than describing it.
Show code cell source
az.plot_posterior(
idata_confounded["rho_tight_spike_slab"], var_names=["beta_O"], figsize=(20, 10)
)
plt.tight_layout();
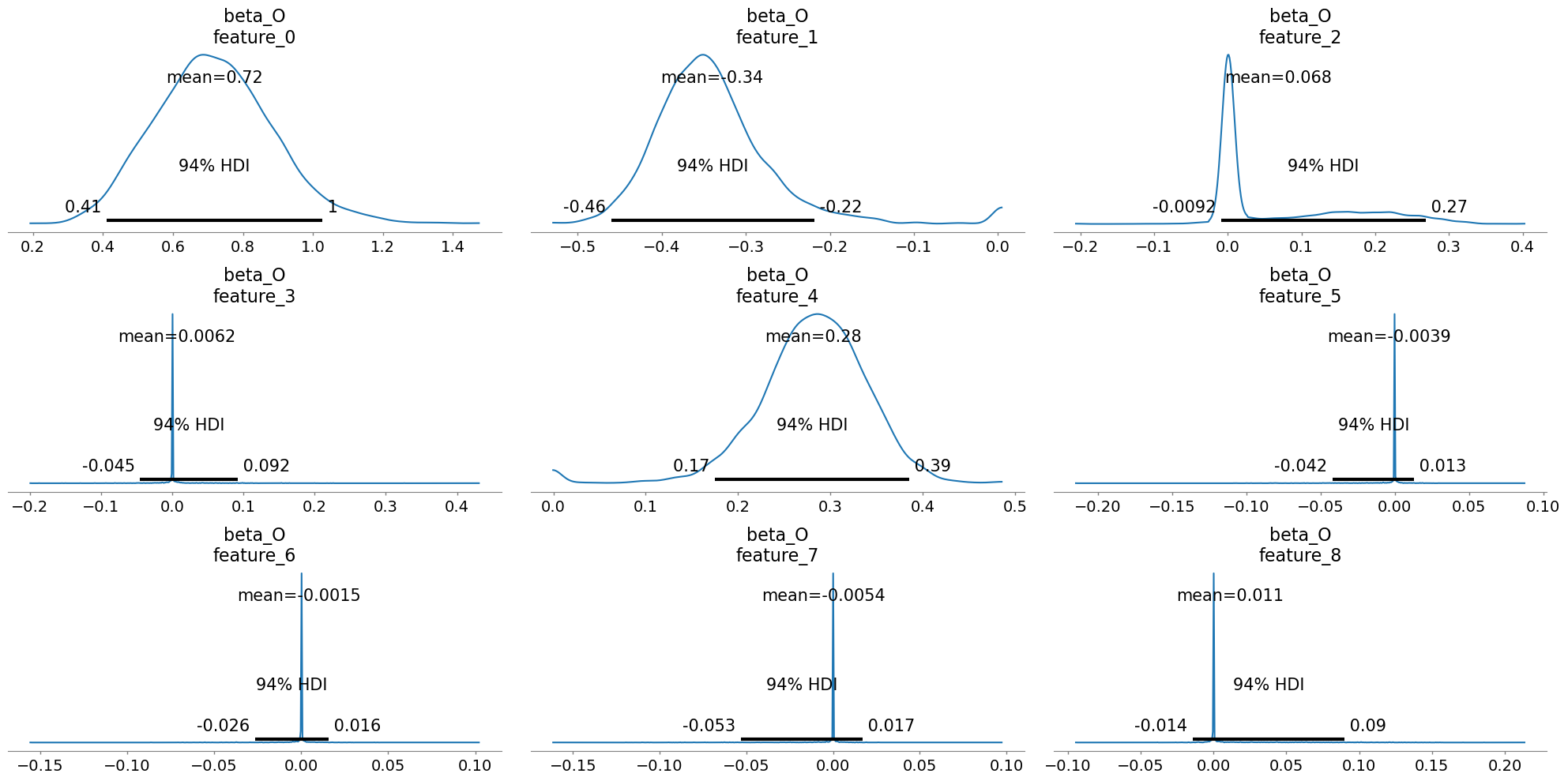
This form of Bayesian regularization is crucial when the analyst suspects structural bias i.e. when some covariates may themselves be noise. By letting the model discover and downweight such variables, these priors act as a safeguard against overfitting endogenous structure. Bayesian variable selection is not merely a statistical convenience, but a structural choice about what relationships should be allowed to persist in the causal model. But this behavior should not be mistaken for a magical salve for endogeneity. No prior, however clever, can know which variables are truly exogenous or which exclusion restrictions are defensible. That judgment must come from theory, domain expertise, and a careful causal design.
Seen this way, these priors are best thought of as complements to theory, not substitutes for it. They are powerful tools for regularization and for exploring the robustness of our inferences, especially in high-dimensional or structurally ambiguous settings. Yet, they should always be deployed with a clear rationale about what the analyst believes to be the relevant sources of variation—and why.
The Binary Treatment Case#
In practice, theory-driven variable selection tends to be more tractable when the treatment is binary. For instance, when a treatment represents a policy adoption, a clinical intervention, or a discrete decision - like entering a program or not. In such settings, the causal question is easier to articulate in design terms: What would have happened if this unit had not received the treatment? Because the intervention is categorical, analysts can often draw on institutional knowledge or policy mechanisms to reason about which variables are genuine confounders, which might serve as instruments, and which can be safely excluded. This clarity of design focus makes the binary treatment context an ideal laboratory for contrasting structural Bayesian modeling with the potential outcomes perspective.
This also allows us to explore how Bayesian joint modeling connects to the potential outcomes framework, where causal effects are conceptualized not just as slopes in a regression, but as differences in counterfactual predictions.To explore this, we adapt our earlier joint modeling setup to the binary treatment context. The model below replaces the continuous treatment equation with a latent variable formulation that links predictors to a Bernoulli decision through a logistic transformation. The latent variables \(U\) and \(V\) introduce correlated residuals between the outcome and treatment equations, controlled by a correlation parameter \(\rho\). This setup captures endogenous selection into the treatment.
data_confounded = simulate_data(n=2500, alpha_true=3, rho=0.6, cate_estimation=True)
coords = {
"beta_outcome": [col for col in data_unconfounded.columns if "feature" in col],
"beta_treatment": [col for col in data_unconfounded.columns if "feature" in col],
"obs": range(data_unconfounded.shape[0]),
"latent": ["U", "V"],
"sigmas_1": ["var_U", "cov_UV"],
"sigmas_2": ["cov_VU", "var_V"],
}
def make_binary_model(
data,
coords,
bart_treatment=False,
bart_outcome=False,
cate_estimation=False,
X=None,
Y=None,
T=None,
priors=None,
observed=True,
spike_and_slab=False,
):
if X is None:
X = data[[col for col in data.columns if "feature" in col]]
Y = data["Y_bin"].values
T = data["T_bin"].values
if priors is None:
priors = {
"rho": [0, 0.5],
"alpha": [0, 10],
"beta_O": [0, 1],
"eps": [0, 1],
"sigma_U": [1],
}
with pm.Model(coords=coords) as binary_model:
X_data = pm.Data("X_data", X.values)
y_data = pm.Data("y_data", Y)
t_data = pm.Data("t_data", T)
alpha = pm.Normal("alpha", priors["alpha"][0], priors["alpha"][1])
sigma_U = pm.HalfNormal("sigma_U", priors["sigma_U"][0])
# just correlation, not full covariance
rho_unconstr = pm.Normal("rho_unconstr", priors["rho"][0], priors["rho"][1])
rho = pm.Deterministic("rho", pm.math.tanh(rho_unconstr)) # keep |rho|<1
inverse_rho = pm.math.sqrt(pm.math.maximum(1 - rho**2, 1e-12))
chol = pt.stack([[sigma_U, 0.0], [sigma_U * rho, inverse_rho]])
# --- Draw latent errors ---
eps_raw = pm.Normal(
"eps_raw", priors["eps"][0], priors["eps"][1], shape=(len(data), 2)
)
eps = pm.Deterministic("eps", pt.dot(eps_raw, chol.T))
U = eps[:, 0]
V = eps[:, 1]
if bart_treatment:
mu_treatment = pmb.BART("mu_treatment_bart", X=X_data, Y=t_data) + V
else:
beta_treatment = pm.Normal("beta_T", 0, 1, dims="beta_treatment")
mu_treatment = pm.Deterministic(
"mu_treatment", (X_data @ beta_treatment) + V
)
p_t = pm.math.invlogit(mu_treatment)
if observed:
_ = pm.Bernoulli("likelihood_treatment", p_t, observed=t_data)
else:
_ = pm.Bernoulli("likelihood_treatment", p_t)
if cate_estimation:
pi_O = pm.Beta("pi_O", alpha=2, beta=2)
alpha_O_raw = pm.Normal("alpha_O_raw", mu=0, sigma=2, dims="beta_outcome")
gamma_O = relaxed_bernoulli(
"gamma_O", pi_O, temperature=0.1, dims="beta_outcome"
)
alpha_interaction_outcome = pm.Deterministic(
"alpha_interact", gamma_O * alpha_O_raw, dims="beta_outcome"
)
alpha = alpha + pm.math.dot(X_data, alpha_interaction_outcome)
if bart_outcome:
mu_outcome = pmb.BART("mu_outcome_bart", X=X_data, Y=y_data) + U
else:
if spike_and_slab:
pi_O = pm.Beta("pi_O_b", alpha=2, beta=2)
beta_O_raw = pm.Normal("beta_O_raw", mu=0, sigma=2, dims="beta_outcome")
gamma_O = relaxed_bernoulli(
"gamma_O_b", pi_O, temperature=0.1, dims="beta_outcome"
)
beta_outcome = pm.Deterministic("beta_O", gamma_O * beta_O_raw)
mu_outcome = pm.Deterministic(
"mu_outcome", (X_data @ beta_outcome) + alpha * t_data + U
)
else:
beta_outcome = pm.Normal(
"beta_O",
priors["beta_O"][0],
priors["beta_O"][1],
dims="beta_outcome",
)
mu_outcome = pm.Deterministic(
"mu_outcome", (X_data @ beta_outcome) + alpha * t_data + U
)
if observed:
_ = pm.Normal(
"likelihood_outcome", mu_outcome, sigma=sigma_U, observed=y_data
)
else:
_ = pm.Normal("likelihood_outcome", mu_outcome, sigma=sigma_U)
return binary_model
binary_model_bart_treatment = make_binary_model(
data_confounded, coords, bart_treatment=True
)
binary_model_bart_treatment_cate = make_binary_model(
data_confounded, coords, bart_treatment=True, cate_estimation=True
)
binary_model = make_binary_model(data_confounded, coords)
binary_model_bart_outcome = make_binary_model(
data_confounded, coords, bart_outcome=True
)
pm.model_to_graphviz(binary_model)

The nested dependency structure of the model can be seen clearly in the graph above. In the binary setting, the, \(\alpha\) parameter captures the average difference in outcomes between treated and untreated units, but as before we are aiming to capture a treatment effect estimate of 3. This model is still bivariate normal in that the latent draws of eps_raw are transformed to reflect the correlation encoded in \(\rho\).
due to the dot product multiplication
This is a convenient representation for the bivariate binary case that samples quite efficiently.
def fit_binary_model(model):
with model:
idata = pm.sample_prior_predictive()
idata.extend(pm.sample(target_accept=0.95))
return idata
idata_binary_model_bart_treatment = fit_binary_model(binary_model_bart_treatment)
idata_binary_model = fit_binary_model(binary_model)
idata_binary_bart_outcome = fit_binary_model(binary_model_bart_outcome)
idata_binary_bart_treatment_cate = fit_binary_model(binary_model_bart_treatment_cate)
Show code cell output
Sampling: [alpha, beta_O, eps_raw, likelihood_outcome, likelihood_treatment, mu_treatment_bart, rho_unconstr, sigma_U]
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_O]
>PGBART: [mu_treatment_bart]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 101 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [alpha, beta_O, beta_T, eps_raw, likelihood_outcome, likelihood_treatment, rho_unconstr, sigma_U]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_T, beta_O]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 29 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [alpha, beta_T, eps_raw, likelihood_outcome, likelihood_treatment, mu_outcome_bart, rho_unconstr, sigma_U]
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_T]
>PGBART: [mu_outcome_bart]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 98 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [alpha, alpha_O_raw, beta_O, eps_raw, gamma_O_u, likelihood_outcome, likelihood_treatment, mu_treatment_bart, pi_O, rho_unconstr, sigma_U]
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, pi_O, alpha_O_raw, gamma_O_u, beta_O]
>PGBART: [mu_treatment_bart]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 241 seconds.
There were 31 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Comparing Treatment Estimates#
Three of our four approaches successfully recover the true causal effect of 3.0, with tight uncertainty bands and accurate confounding estimates. But when BART enters the outcome equation, the results collapse: the treatment effect estimate drops to near-zero. This is not a sampling failure. Diagnostics show healthy chains, good ESS, and converged r-hat values. The model is doing exactly what we asked it to do. The problem is what we asked the model to do!
Show code cell source
fig, axs = plt.subplots(2, 2, figsize=(20, 6), sharex=True)
axs = axs.flatten()
az.plot_posterior(idata_binary_model_bart_treatment, var_names="alpha", ax=axs[0])
az.plot_posterior(idata_binary_bart_outcome, var_names="alpha", ax=axs[1])
az.plot_posterior(idata_binary_model, var_names="alpha", ax=axs[2])
az.plot_posterior(idata_binary_bart_treatment_cate, var_names="alpha", ax=axs[3])
for ax, title in zip(
axs, ["bart_treatment", "bart_outcome", "no_bart", "bart_treatment_cate"]
):
ax.axvline(3, linestyle="--", color="k")
ax.set_title(f"Model: {title}")
plt.tight_layout()
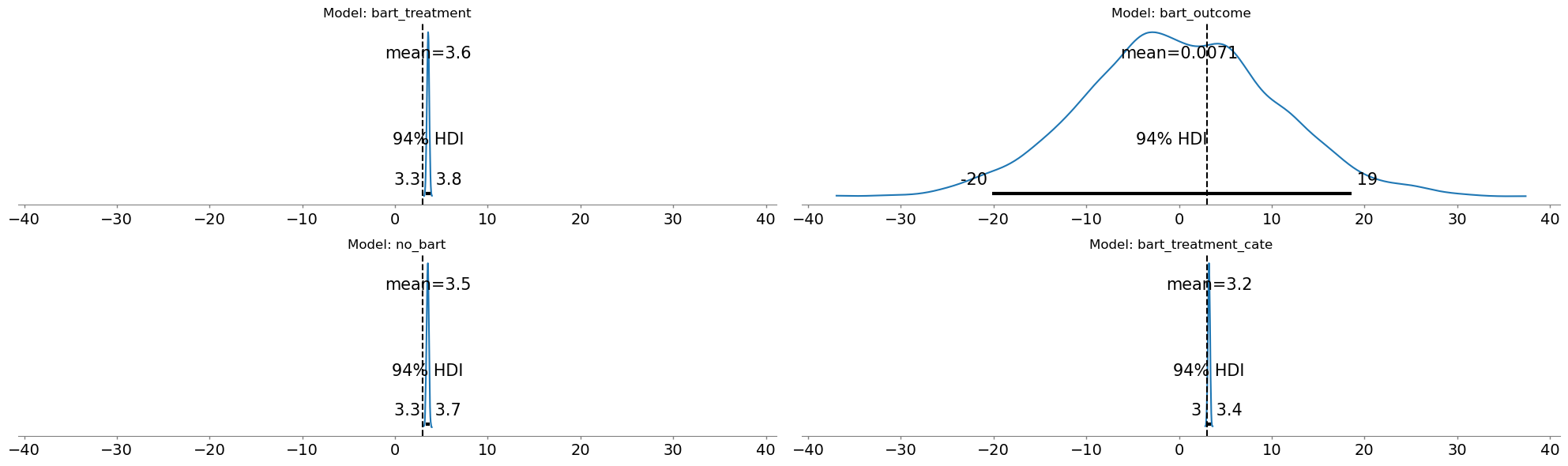
The failure stems from a fundamental tension between flexibility and causal identification. In our data generating process the treatment is strongly predicted by the covariates. The flexibility of the BART outcome model picks up on this pattern. It learns the total association and does not distinguish causal relationships from association. When we then add a structural parameter α for the treatment effect, we’re asking: what is the effect of the treatment after BART has already explained outcome variation using the treatment predictive features. We can see this reflected in the \(\rho\) parameter for the BART outcome model.
Show code cell source
pd.concat(
{
"linear_no_bart": az.summary(idata_binary_model, var_names=["alpha", "rho"]),
"bart_treatment": az.summary(
idata_binary_model_bart_treatment, var_names=["alpha", "rho"]
),
"bart_outcome": az.summary(
idata_binary_bart_outcome, var_names=["alpha", "rho"]
),
"bart_treatment_cate": az.summary(
idata_binary_bart_treatment_cate, var_names=["alpha", "rho"]
),
}
)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | ||
|---|---|---|---|---|---|---|---|---|---|---|
| linear_no_bart | alpha | 3.523 | 0.124 | 3.289 | 3.749 | 0.006 | 0.002 | 454.0 | 1068.0 | 1.01 |
| rho | 0.542 | 0.057 | 0.431 | 0.645 | 0.003 | 0.001 | 379.0 | 827.0 | 1.01 | |
| bart_treatment | alpha | 3.561 | 0.125 | 3.337 | 3.806 | 0.006 | 0.003 | 445.0 | 997.0 | 1.02 |
| rho | 0.520 | 0.054 | 0.422 | 0.629 | 0.003 | 0.001 | 367.0 | 826.0 | 1.02 | |
| bart_outcome | alpha | 0.007 | 10.257 | -20.138 | 18.611 | 0.134 | 0.174 | 5901.0 | 2583.0 | 1.00 |
| rho | 0.974 | 0.011 | 0.954 | 0.992 | 0.000 | 0.000 | 3294.0 | 2713.0 | 1.00 | |
| bart_treatment_cate | alpha | 3.230 | 0.113 | 3.026 | 3.450 | 0.005 | 0.002 | 586.0 | 1245.0 | 1.00 |
| rho | 0.746 | 0.062 | 0.635 | 0.866 | 0.003 | 0.002 | 426.0 | 698.0 | 1.01 |
The bart_outcome model places weight on the correlation between treatment and outcome rather than parcel out the share of impact into the treatment and confounding relationship. The causal effect absorbed into the covariate adjustment of the BART component, and we have a fundamental misattribution which makes recovery of structural parameter impossible in this set up. The other two BART model specifications; bart_treatment and bart_treatment_cate correctly identify the structural parameter because the BART component is used to flexibly model the treatment status. The structural parameter \(\alpha\) remains identifiable as the average or baseline effect because we’ve partialied out the variation in the outcome explicitly. The more traditional linear_no_bart model does not have the flexibility to absorb the causal effect into a non-linear component. As such, the structural parameter remains identifiable. This is one of the virtues of “simpler” models.
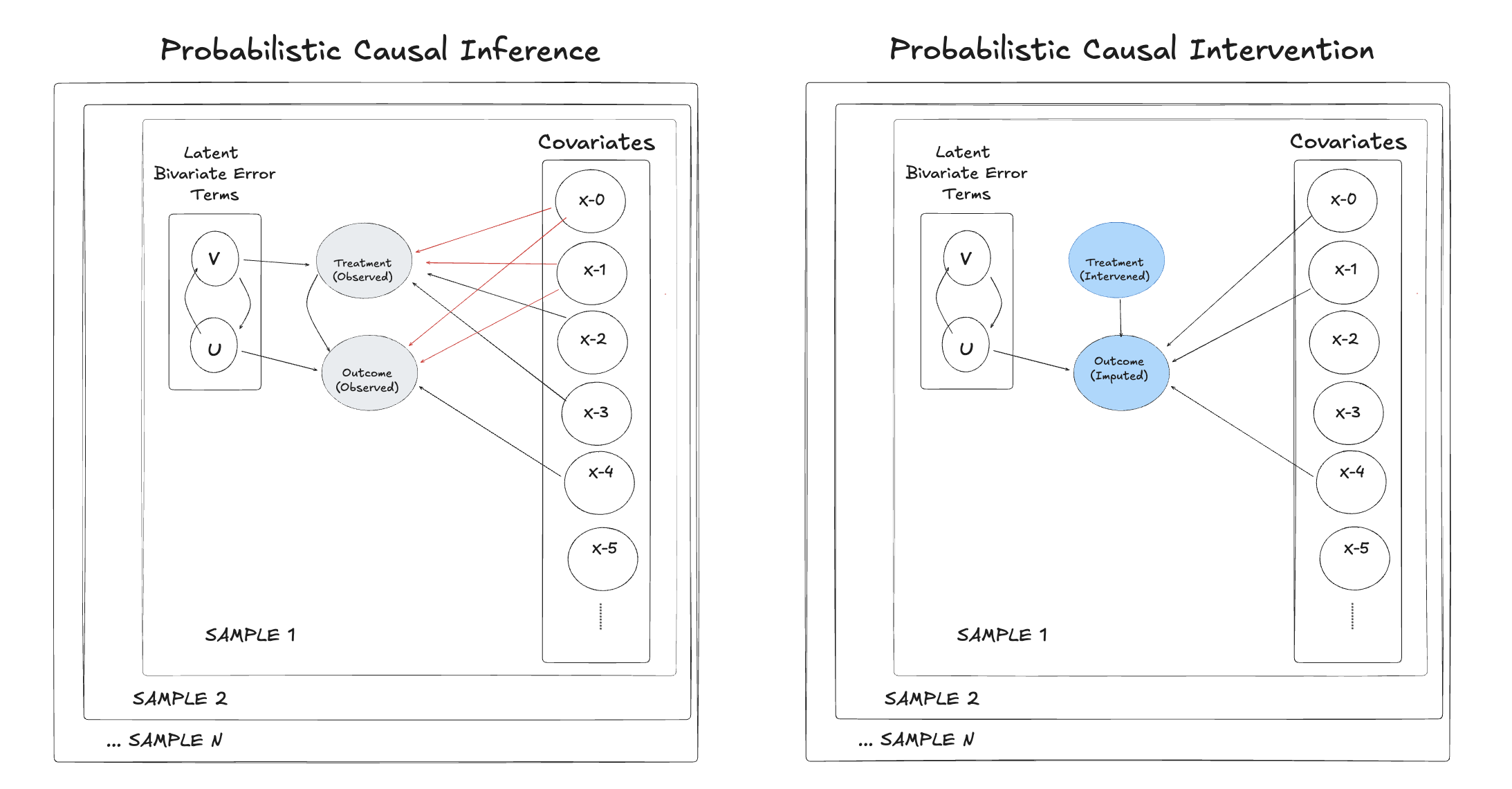
Non-Parametric Causal Inference#
We might worry that these parametric approaches to identifying causal effects hide the real lesson. Non-parametric approximation functions can still learn the correct expected value function and we ought to derive causal estimates via the imputation of potential outcomes.
We should verify that the BART-outcome model’s failure isn’t merely a problem with how we’ve extracted the treatment effect parameter \(\alpha\). Perhaps the structural parameter collapsed, but the model could still recover causal effects through direct counterfactual imputation. Rather than interpreting a regression coefficient, we directly simulate potential outcomes:
Fit a model for \(E[Y | X, T]\) (however flexible)
Impute \(Y(1)\): Set everyone to treated, predict outcomes
Impute \(Y(0)\): Set everyone to control, predict outcomes
Compute ATE: Average the difference \(Y(1) - Y(0)\)
This approach is appealing because it doesn’t require interpreting structural parameters. If the model has learned the correct conditional expectation function, counterfactual imputation should recover the true causal effect—even if \(\alpha\) itself is uninterpretable. This process of imputation is then repeated across many, many samples to derive the posterior distribution of the treatment effect.
def impute_potential_outcomes(model, idata, n=2500):
with model:
# Posterior predictive under treatment
pm.set_data({"t_data": np.ones(n, dtype="int")})
Y1 = pm.sample_posterior_predictive(idata, var_names=["likelihood_outcome"])
# Posterior predictive under control
pm.set_data({"t_data": np.zeros(n, dtype="int")})
Y0 = pm.sample_posterior_predictive(idata, var_names=["likelihood_outcome"])
ATE = (
Y1["posterior_predictive"]["likelihood_outcome"]
- Y0["posterior_predictive"]["likelihood_outcome"]
).mean()
print("Imputed Difference in Potential Outcomes", ATE.item())
return Y1, Y0, ATE.item()
y1_bart_treatment, y0_bart_treatment, ate_bart_treatment = impute_potential_outcomes(
binary_model_bart_treatment, idata_binary_model_bart_treatment
)
y1_bart_outcome, y0_bart_outcome, ate_bart_outcome = impute_potential_outcomes(
binary_model_bart_outcome, idata_binary_bart_outcome
)
y1_no_bart, y0_no_bart, ate_linear = impute_potential_outcomes(
binary_model, idata_binary_model
)
y1_treatment_cate, y0_treatment_cate, ate_cate = impute_potential_outcomes(
binary_model_bart_treatment_cate, idata_binary_bart_treatment_cate
)
imputed_effects = pd.DataFrame(
{
"model": [
"bart_treatment",
"bart_outcome",
"linear_no_bart",
"bart_treatment_cate",
],
"ate": [ate_bart_treatment, ate_bart_outcome, ate_linear, ate_cate],
}
)
Show code cell output
Sampling: [likelihood_outcome]
Sampling: [likelihood_outcome]
Sampling: [likelihood_outcome]
Imputed Difference in Potential Outcomes 3.563278983428259
Sampling: [likelihood_outcome]
Sampling: [likelihood_outcome]
Imputed Difference in Potential Outcomes 0.0003075874678246132
Sampling: [likelihood_outcome]
Sampling: [likelihood_outcome]
Imputed Difference in Potential Outcomes 3.524198759477424
Sampling: [likelihood_outcome]
Imputed Difference in Potential Outcomes 3.230870608602349
In the above code we have applied the following process to impute potential outcomes for each individual under different treatment regimes.
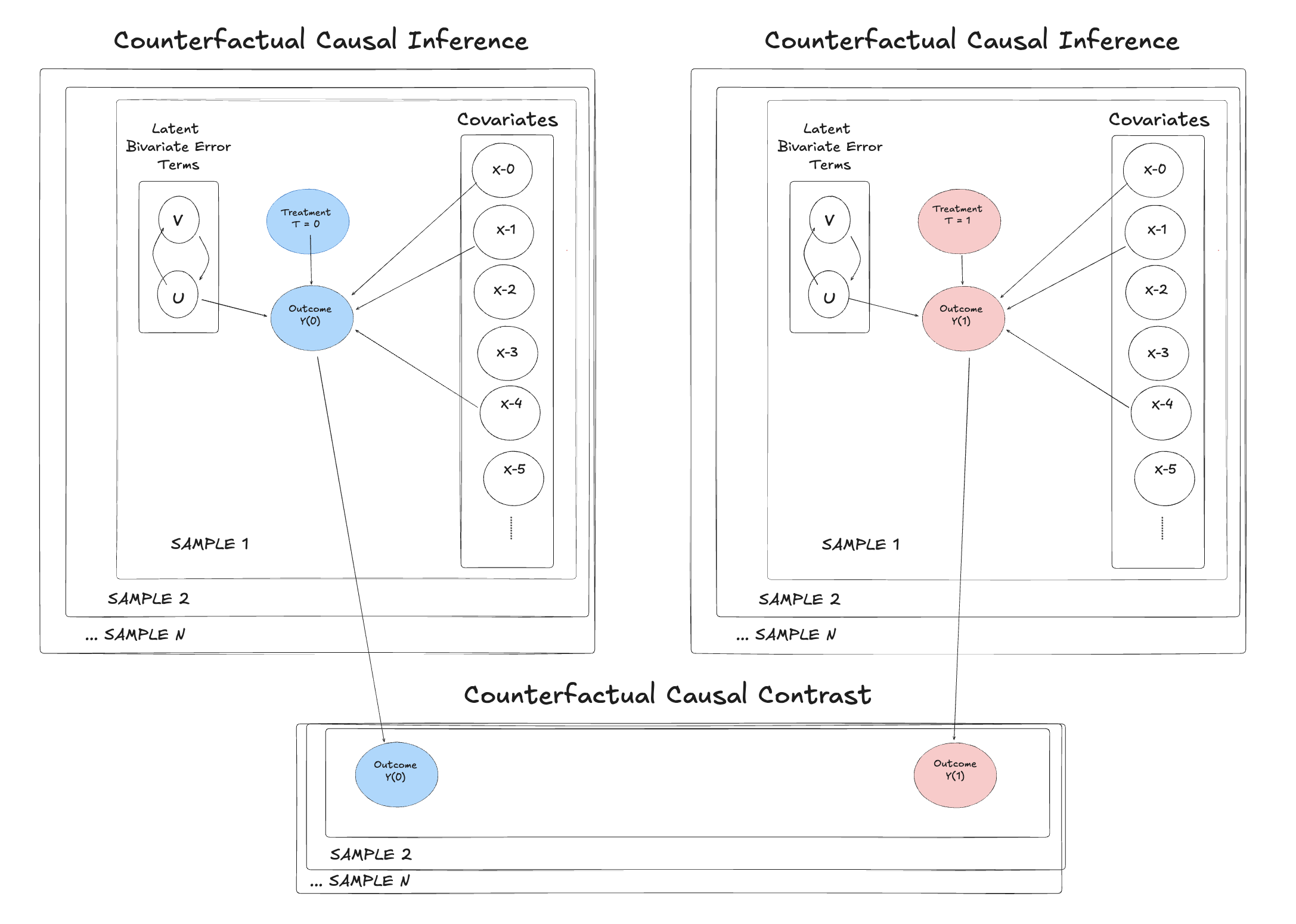
The results are striking in their consistency. For the three successful specifications, both methods of extracting causal effects agree. For the bart_outcome specification the Imputation approach to causal inference also fails. This is crucial. The failure is not about how we interrogate the model, but about what the model learned during fitting.
imputed_effects
| model | ate | |
|---|---|---|
| 0 | bart_treatment | 3.563279 |
| 1 | bart_outcome | 0.000308 |
| 2 | linear_no_bart | 3.524199 |
| 3 | bart_treatment_cate | 3.230871 |
In prediction tasks, BART’s flexibility is a pure advantage. It finds patterns we didn’t know to look for, captures complex interactions automatically, and often achieves superior out-of-sample accuracy. But in causal inference, this same flexibility becomes a liability when it absorbs the variation we’re trying to causally attribute. The problem is structural: any sufficiently flexible method faces this challenge. Methods that can perfectly adapt their functional form to training data will inadvertently learn causal pathways as associational patterns, unless the structure learning is constrained to partial out the treatment influences. The stronger the relationship between the predictors of the outcome and the treatment, the more we can expect to see this collapse. Flexible outcome modelling may be useful in cases where the relationship between treatment and covariates is truly independent, but it presents a risk where the focus is on recovering treatment effects.
Conditional Average Treatment Effects#
The BART-treatment model demonstrated that flexibility in the treatment equation doesn’t harm identification. We can also introduce flexibility in how treatment effects vary with covariates, while preserving the interpretability and identifiability of structural parameters? Our bart_treatment_cate model allows this by interacting the treatment parameter with the covariates. This explicitly parameterize effect heterogeneity. Unlike BART in the outcome equation (which failed because it absorbed the entire treatment signal), interaction terms allow treatment effects to vary while retaining a structural interpretation. This allows flexibility while retaining identifiability.
We can see this flexibility by pulling out the ITE (individual treatment effects) estimates, using the potential outcomes imputations. We can compare the ITEs across the bart_treatment_cate and linear_no_bart models.
Show code cell source
cate = (
y1_treatment_cate["posterior_predictive"]["likelihood_outcome"]
- y0_treatment_cate["posterior_predictive"]["likelihood_outcome"]
)
sample_cate = (
cate.mean(dim=("chain", "draw"))
.to_dataframe()
.sample(100)
.sort_values("likelihood_outcome")
)
cate_linear = (
y1_no_bart["posterior_predictive"]["likelihood_outcome"]
- y0_no_bart["posterior_predictive"]["likelihood_outcome"]
)
res = smf.ols(
"""Y_bin ~ T_bin + feature_0 + feature_1 + feature_2 + feature_3 + feature_4 + feature_5 + feature_6 + feature_7 + feature_8""",
data,
).fit()
ols_est = res.params["T_bin"]
fig, axs = plt.subplots(1, 2, figsize=(15, 20))
axs = axs.flatten()
ax = az.plot_forest(
cate_linear,
combined=True,
figsize=(15, 15),
coords={"likelihood_outcome_dim_0": sample_cate.index},
ax=axs[0],
)
axs[0].axvline(3, color="red", label="True Treatment Effect")
axs[0].axvline(ols_est, color="darkgreen", label="OLS Estimate")
axs[0].legend()
axs[0].set_title("ITE Linear-Model estimates \n Random Sample of 100")
ax = az.plot_forest(
cate,
combined=True,
figsize=(15, 10),
coords={"likelihood_outcome_dim_0": sample_cate.index},
ax=axs[1],
)
axs[1].axvline(3, color="red", label="True Treatment Effect")
axs[1].axvline(ols_est, color="darkgreen", label="OLS Estimate")
axs[1].set_title("ITE CATE-Model estimates \n Random Sample of 100")
n = len(sample_cate.index)
n_order = range(n, 0, -1)
axs[1].scatter(data_confounded.iloc[sample_cate.index]["alpha"], n_order, color="black")
axs[1].legend()
plt.tight_layout();

This comparison shows how the flexibility of treatment effects can be incorporated without losing interpretability.
An Empirical Application#
We will now explore an example with a real data set from the NHEFS study about the effects of quitting smoking on weight. Ultimately we will compare our estimates of treatment effects to a well specified and sensible regression model. The goal is not to provide the regression estimate as a source of truth, but to show the reasonable diversity of views we can achieve while aiming to estimate causal impact.
import causalpy as cp
df_nhefs = cp.load_data("nhefs")
features = [
"age",
"race",
"sex",
"smokeintensity",
"smokeyrs",
"wt71",
"active_1",
"active_2",
"education_2",
"education_3",
"education_4",
"education_5",
"exercise_1",
"exercise_2",
]
X = df_nhefs[features]
X = (X - X.mean(axis=0)) / X.std(axis=0)
Y = df_nhefs["outcome"].values
T = df_nhefs["trt"].values
coords = {
"beta_outcome": features,
"beta_treatment": features,
"obs": range(df_nhefs.shape[0]),
"latent": ["U", "V"],
"sigmas_1": ["var_U", "cov_UV"],
"sigmas_2": ["cov_VU", "var_V"],
}
priors = {
"rho": [0.0, 0.5],
"alpha": [0, 3],
"beta_O": [0, 3],
"eps": [0, 1],
"sigma_U": [0.5],
}
nhefs_binary_model = make_binary_model(
df_nhefs,
coords,
bart_treatment=False,
cate_estimation=False,
X=X,
Y=Y,
T=T,
priors=priors,
observed=False,
)
pm.model_to_graphviz(nhefs_binary_model)

The model is specified without the observed outcomes deliberately. We feed in the predictor \(X\) and now we validate how the model specification can recover accurate treatment effects.
Parameter Recovery#
We “forward” sample from the system with known parameters. This generates a synthetic observation data that we will feed back into the model, to condition on data known to have been sampled from this model. This makes use of PyMC’s do-syntax. We are intervening on the data generating process to set values of the parameters in the system.
fixed_parameters = {
"rho": 0.6,
"alpha": 3,
"beta_O": [0, 1, 0.4, 0.3, 0.1, 0.8, 0, 0, 0, 0, 0, 0, 3, 0],
"beta_T": [1, 1.3, 0.5, 0.3, 0.7, 1.6, 0, 0.4, 0, 0, 0, 0, 0, 0],
}
with pm.do(nhefs_binary_model, fixed_parameters) as synthetic_model:
idata = pm.sample_prior_predictive(
random_seed=1000
) # Sample from prior predictive distribution.
synthetic_y = idata["prior"]["likelihood_outcome"].sel(draw=0, chain=0)
synthetic_t = idata["prior"]["likelihood_treatment"].sel(draw=0, chain=0)
Sampling: [eps_raw, likelihood_outcome, likelihood_treatment, rho_unconstr, sigma_U]
We now infer the probable parameters conditioned on the synthetic observed dats. That is, we condition our model on the data generated in our forward pass and attempt the backwards inference. Given the synthetic observations what is the most plausible parameterisation of the world-state that generated the data?
# Infer parameters conditioned on observed data
with pm.observe(
nhefs_binary_model,
{"likelihood_outcome": synthetic_y, "likelihood_treatment": synthetic_t},
) as inference_model:
idata_sim = pm.sample_prior_predictive()
idata_sim.extend(pm.sample(random_seed=100, chains=4, tune=2000, draws=500))
Sampling: [alpha, beta_O, beta_T, eps_raw, likelihood_outcome, likelihood_treatment, rho_unconstr, sigma_U]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_T, beta_O]
Sampling 4 chains for 2_000 tune and 500 draw iterations (8_000 + 2_000 draws total) took 13 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
The inferential move allows us to accurately recover the focal parameters.
Show code cell source
ax = az.plot_pair(idata_sim, var_names=["alpha", "rho"], kind="kde", figsize=(15, 4))
ax.axhline(0.6, linestyle="--", color="red", label="True Rho")
ax.axvline(3, linestyle="--", color="black", label="True Alpha")
ax.set_title("Parameter Recovery with NHEFS data")
ax.legend();
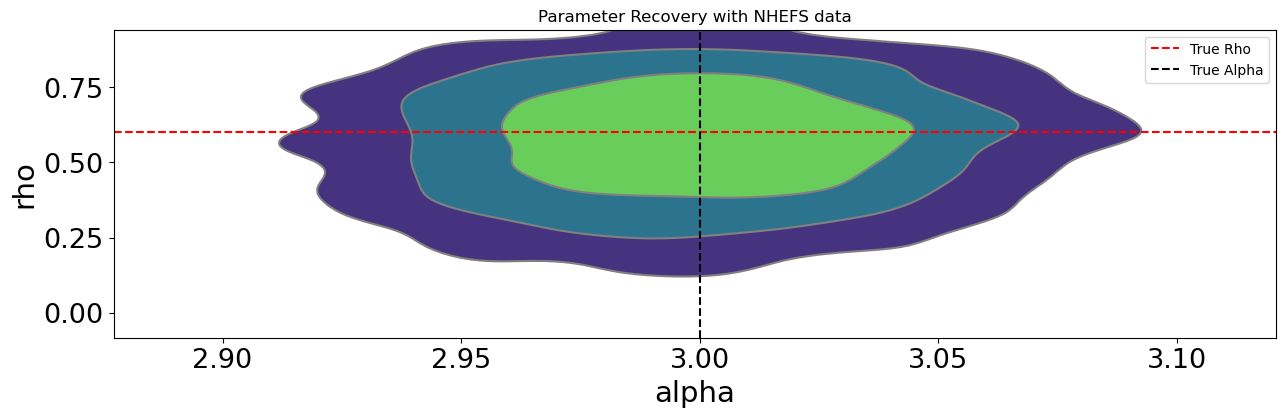
The parameter recovery is also extended to the covariate weights in the system. This is promising. It suggests that our model is able to recover true parameters from the data. Recovering covariate weights validates that the model correctly decomposes variation across the entire causal system, not just the focal treatment parameter.”
az.plot_posterior(idata_sim, var_names=["beta_O"], ref_val=fixed_parameters["beta_O"]);
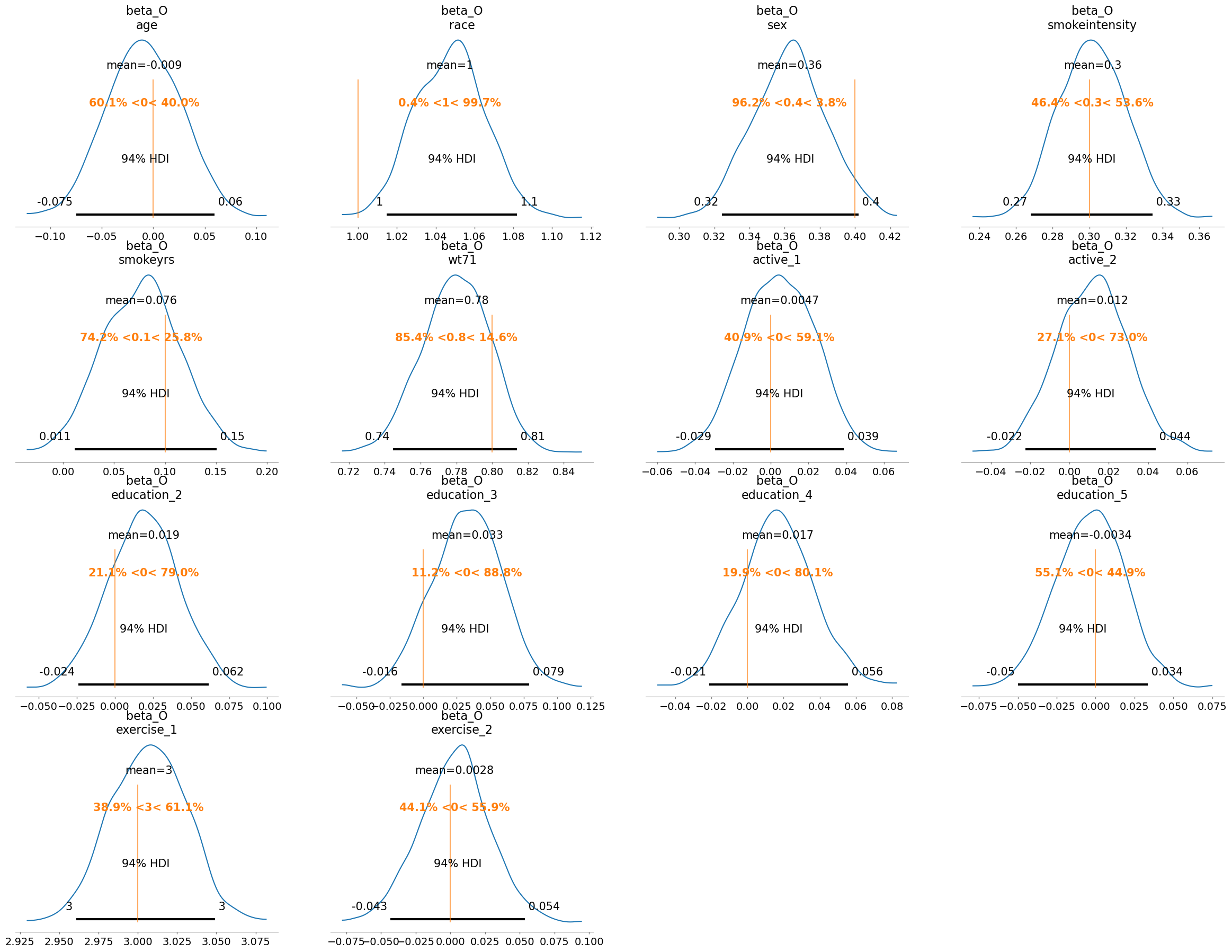
Conditional Update on Observed Data#
Next we will condition on the actual observed data and apply a range of priors to the \(\rho\) term to test the sensitivity of our findings to prior weights.
sampler_kwargs = {
"tune": 2000,
"draws": 1000,
"target_accept": 0.95,
"mp_ctx": "spawn",
"random_seed": 1040,
# "cores": 1
}
priors = {
"rho": [0.0, 0.5],
"alpha": [0, 3],
"beta_O": [0, 3],
"eps": [0, 1],
"sigma_U": [0.5],
}
priors_no_confounding = {
"rho": [0.0, 0.001],
"alpha": [0, 3],
"beta_O": [0, 3],
"eps": [0, 1],
"sigma_U": [0.5],
}
nhefs_binary_model = make_binary_model(
df_nhefs,
coords,
bart_treatment=False,
cate_estimation=False,
X=X,
Y=Y,
T=T,
priors=priors,
observed=True,
)
nhefs_binary_model_cate = make_binary_model(
df_nhefs,
coords,
bart_treatment=True,
cate_estimation=True,
X=X,
Y=Y,
T=T,
priors=priors,
observed=True,
)
nhefs_binary_model_0_rho = make_binary_model(
df_nhefs,
coords,
bart_treatment=False,
cate_estimation=False,
X=X,
Y=Y,
T=T,
priors=priors_no_confounding,
observed=True,
)
nhefs_binary_model_s_s = make_binary_model(
df_nhefs,
coords,
bart_treatment=False,
cate_estimation=False,
X=X,
Y=Y,
T=T,
priors=priors,
observed=True,
spike_and_slab=True,
)
with nhefs_binary_model:
idata_nhefs = pm.sample_prior_predictive()
idata_nhefs.extend(
pm.sample(**sampler_kwargs, idata_kwargs={"log_likelihood": True})
)
with nhefs_binary_model_cate:
idata_nhefs_cate = pm.sample_prior_predictive()
idata_nhefs_cate.extend(
pm.sample(**sampler_kwargs, idata_kwargs={"log_likelihood": True})
)
with nhefs_binary_model_0_rho:
idata_nhefs_0_rho = pm.sample_prior_predictive()
idata_nhefs_0_rho.extend(
pm.sample(**sampler_kwargs, idata_kwargs={"log_likelihood": True})
)
with nhefs_binary_model_s_s:
idata_nhefs_s_s = pm.sample_prior_predictive()
idata_nhefs_s_s.extend(
pm.sample(**sampler_kwargs, idata_kwargs={"log_likelihood": True})
)
Show code cell output
Sampling: [alpha, beta_O, beta_T, eps_raw, likelihood_outcome, likelihood_treatment, rho_unconstr, sigma_U]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_T, beta_O]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 39 seconds.
Sampling: [alpha, alpha_O_raw, beta_O, eps_raw, gamma_O_u, likelihood_outcome, likelihood_treatment, mu_treatment_bart, pi_O, rho_unconstr, sigma_U]
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, pi_O, alpha_O_raw, gamma_O_u, beta_O]
>PGBART: [mu_treatment_bart]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 179 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Sampling: [alpha, beta_O, beta_T, eps_raw, likelihood_outcome, likelihood_treatment, rho_unconstr, sigma_U]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_T, beta_O]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 38 seconds.
Sampling: [alpha, beta_O_raw, beta_T, eps_raw, gamma_O_b_u, likelihood_outcome, likelihood_treatment, pi_O_b, rho_unconstr, sigma_U]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, sigma_U, rho_unconstr, eps_raw, beta_T, pi_O_b, beta_O_raw, gamma_O_b_u]
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 174 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
The predictive comparison shows effectively comparable model performance metrics, with the linear model exhibited the “best” metric.
Show code cell source
compare_df = az.compare(
{
"nhefs_binary_linear": idata_nhefs,
"nhefs_bart_cate": idata_nhefs_cate,
"nhefs_rho_0": idata_nhefs_0_rho,
"nhefs_s_s": idata_nhefs_s_s,
},
var_name="likelihood_outcome",
)
az.plot_compare(compare_df);
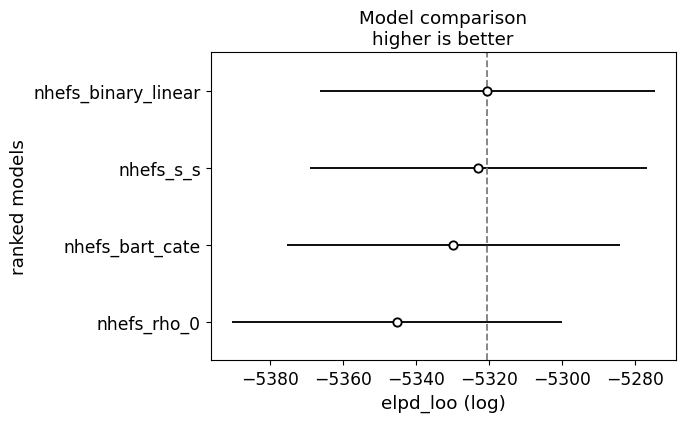
The parameters are well identified across all model specifications.
pd.concat(
{
"nhefs_binary_linear": az.summary(idata_nhefs, var_names=["alpha", "rho"]),
"nhefs_bart_cate": az.summary(idata_nhefs_cate, var_names=["alpha", "rho"]),
"nhefs_rho_0": az.summary(idata_nhefs_0_rho, var_names=["alpha", "rho"]),
"nhefs_slate_slab": az.summary(idata_nhefs_s_s, var_names=["alpha", "rho"]),
}
)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | ||
|---|---|---|---|---|---|---|---|---|---|---|
| nhefs_binary_linear | alpha | 6.819 | 0.421 | 6.022 | 7.577 | 0.012 | 0.006 | 1324.0 | 2339.0 | 1.01 |
| rho | -0.175 | 0.025 | -0.220 | -0.127 | 0.001 | 0.000 | 931.0 | 2193.0 | 1.01 | |
| nhefs_bart_cate | alpha | 8.380 | 0.621 | 7.218 | 9.547 | 0.037 | 0.015 | 283.0 | 769.0 | 1.01 |
| rho | -0.229 | 0.043 | -0.311 | -0.150 | 0.003 | 0.001 | 251.0 | 673.0 | 1.01 | |
| nhefs_rho_0 | alpha | 5.170 | 0.372 | 4.479 | 5.881 | 0.007 | 0.005 | 2808.0 | 2768.0 | 1.00 |
| rho | -0.000 | 0.001 | -0.002 | 0.002 | 0.000 | 0.000 | 7234.0 | 2770.0 | 1.00 | |
| nhefs_slate_slab | alpha | 6.683 | 0.426 | 5.832 | 7.440 | 0.014 | 0.007 | 994.0 | 1915.0 | 1.00 |
| rho | -0.170 | 0.025 | -0.216 | -0.123 | 0.001 | 0.000 | 772.0 | 1334.0 | 1.00 |
resulting in a treatment effect estimate greater than the baseline OLS assumption. We can also assess the Bayes factor i.e. the comparison of each model under a particular null hypothesis. Here we compare each model to the null of the OLS estimate.
fig, axs = plt.subplots(2, 2, figsize=(20, 6))
axs = axs.flatten()
feature_str = " + ".join(features)
formula = "outcome ~ trt +" + feature_str
res = smf.ols(
formula,
df_nhefs,
).fit()
ols_est = res.params["trt"]
az.plot_bf(idata_nhefs, var_name="alpha", ref_val=ols_est, ax=axs[0])
az.plot_bf(idata_nhefs_cate, var_name="alpha", ref_val=ols_est, ax=axs[1])
az.plot_bf(idata_nhefs_0_rho, var_name="alpha", ref_val=ols_est, ax=axs[2])
az.plot_bf(idata_nhefs_s_s, var_name="alpha", ref_val=ols_est, ax=axs[3])
axs[0].set_xlabel(""" alpha \n Linear Model """)
axs[1].set_xlabel(""" alpha \n BART CATE Model """)
axs[2].set_xlabel(""" alpha \n Rho at 0 Model """)
axs[3].set_xlabel(""" alpha \n Linear Spike and Slab """);
arviz - WARNING - The reference value is outside of the posterior. This translate into infinite support for H1, which is most likely an overstatement.
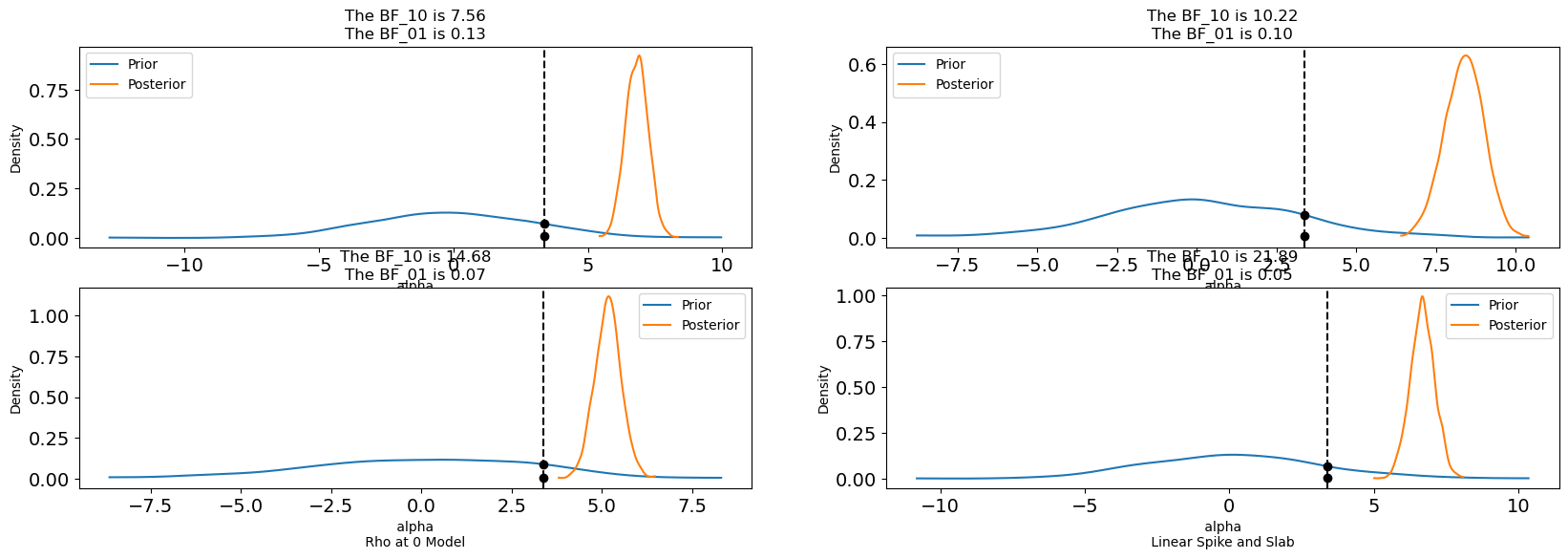
The results all indicate a positive effect on weight due to the quitting smoking. They vary slightly in the attributed effect but, interestingly even if we try to zero out the correlation between treatment and outcome the model still implies a higher effect than observed in the simpler regression model. The Bayes factor plots report that the alternative hypothesis \(\alpha \neq 3.3\) is between 5 and 40 times more likely than the null hypothesis of \(\alpha = 3.3\). They also indicate the effect of Bayesian updating by the extent in which the posterior has transformed from the prior in each plot. Interestingly, these array of results suggests the treatment estimate is sensitive to the endogeneity correction. Allowing \(\rho \neq 0\) increases the estimated effect (from ~5 to ~6). That means the joint model is using the estimated correlation between unobservables to further adjust the treatment coefficient beyond what the model with \(\rho = 0\) does. To top this off, the sign of the \(\rho\) estimate matters. When \(\rho\) is allowed to vary, the posterior estimate forces the correlation between treatment propensity and outcome measure negative. In other words, the propensity to quit is associated with less weight gain. By modelling this relationship as a correlation, the \(\alpha\) parameter is not forced to reflect this pattern, and the model can attribute a higher effect to the treatment intervention than we found with the OLS estimate.
Applying These Methods#
The models demonstrated here are not recipes to be followed mechanically but frameworks for making structural assumptions explicit. Before fitting a Bayesian causal model to real data, ask yourself three questions:
First: Can I defend my causal structure theoretically? Which variables do you believe are confounders, which are instruments, which are irrelevant? Write down your causal graph before writing down your priors. If you cannot justify exclusion restrictions through domain knowledge or institutional understanding, data-driven variable selection will not rescue you—it will merely dress speculation in statistical clothing.
Second: How sensitive are my conclusions to structural assumptions? The confounding parameter \(\rho\) is rarely identified from observables alone. Vary your priors on ρ across plausible ranges and observe how your treatment effect estimate shifts. Fit models with normal priors, sparse priors, and theory-driven exclusions. If your causal conclusions are stable across specifications, they’re robust. If they vary dramatically, that variation is real epistemic uncertainty and should be reported as such.
Third: Where have I placed flexibility, and why? Automated variable selection and nonparametric methods are powerful tools, but flexibility in the outcome equation can absorb the causal effects you’re trying to estimate. As we demonstrated with BART, sufficiently flexible outcome models learn total associations rather than structural parameters. Use flexibility in the treatment equation if needed, but keep the outcome equation constrained to interpretable causal parameters.
Conclusion#
These questions point to what distinguishes structural modeling from purely associational approaches. When we specify a Bayesian causal model, we write down a probabilistic program that encodes our beliefs about how data are generated—which variables influence which, how uncertainty enters, what exclusions hold. Once fitted, the model becomes a working machine we can run forward under interventions, perturb in its assumptions, and interrogate for consequences. This executable character lets us simulate alternative worlds and test the coherence of our causal story, rather than merely report coefficients.
The virtue of treating causal models as probabilistic programs is twofold. First, it forces us to articulate our causal beliefs explicitly i.e. the graphical, functional, and stochastic components that make the model run. Second, it offers a disciplined way to explore what follows from those beliefs under uncertainty. Bayesian structural causal inference therefore unites an epistemic modesty with computational rigor: each model is a local, provisional machine for generating causal understanding, not a final map of the world.
The credibility revolution’s achievement was recognizing that causal claims require more than correlations. Causal inference requires identification strategies. These strategies try to bracket complexity through design. Bayesian structural modeling takes a complementary path: it models complexity explicitly, then explores how robust our conclusions are to structural perturbations. Both approaches succeed when we know not only how our models work, but where they stop working.
Every causal model, like every fish tank, is a “small world” whose regularities we can nurture but never universalize. Our task is not to master the ocean, but to build clear tanks and learn when to change the water.
References#
J. Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2000. ISBN 9780521773621. URL: https://books.google.ie/books?id=wnGU_TsW3BQC.
J.D. Angrist and J.S. Pischke. Mostly Harmless Econometrics: An Empiricist's Companion. Princeton University Press, 2009. ISBN 9780691120355. URL: https://books.google.ie/books?id=YSAzEAAAQBAJ.
Bruce E Hansen. Econometrics. Princeton, 2022.
P Aronow and B Miller. Foundations of Agnostic Statistics. Cambridge University Press, 2019.
David Kaplan. Bayesian Statistics for the social sciences. Guilford Press, 2024.